

ניטור או observability של האפליקציה שלך בענן הוא חלק מהותי ממחזור חיי פיתוח של האפליקציה (Development Life Cycle), אנחנו נעבור צעד אחר צעד על הדרכים השונות ב-AWS לניטור האפליקציה שלך. זהו נושא ענק, שלא ניתן להכניסו בבלוג בודד, בשבועות הקרובים, אוציא מספר בלוגים שעוסקים בנושא, זה הראשון מביניהם.
נתחיל בלהבין מה הכוונה בניטור.
מהו ניטור
ניטור היא היכולת להבין בכל רגע נתון :
האם הכל תקין.
במידה ולא, לאפשר למפתחים להבין מה גורם לדברים להתנהג כפי שהם מתנהגים.
ישנן המון דרכים לתקוף את שתי הנקודות הללו, ומסביב לכל פתרון קם לו סטרטאפ או מוצר כלשהו, זה עולם רחב מאוד, עם המון פתרונות ומוצרים, אך בסופו של דבר רוב רובם של המוצרים מתכנסים לשלושה דרכים שונות לנטר את הענן:
לוגים (Logs) - שורות טקסט שהמפתחים אופים לתוך הקוד שהם כותבים, ברגע שישנה בעיה, ניגשים למערכת שמנגישה את הלוגים ומתחילים לחפש אחר רמזים לבעיה. הפתרון הזה נופל תחת הקטגוריה של ״היכולת להבין מה הבעיה״.
מטריקות (Metrics) - ברכב שלכם יש שעונים שונים שמודדים מדדים שונים כגון סל״ד, מד דלק, טמפ ועוד. שעון הסל״ד מקבל בכל רגע נתון את מהירות המנוע אבל מהירות המנוע בכל חלקיק שניה משתנה, במידה והוא היה מראה לכם את המהירות האמיתית בכל רגע נתון, השעון היה קופץ לכם בפראות, במקום זאת הוא מציג לכם את מהירות המנוע הממוצעת לפרק זמן מסוים.
בעצם מנוע מטריקות יודע לאסוף מדד (מטריקה) מסוים לאורך זמן, להפעיל עליו פונקציה סטטיסטית כגון ממוצע, חציון, כמות בפרק זמן מסוים, לדוגמא חציון של כל המטריקות שנאספו בפרק זמן של דקה ולהציג לכם את זה. בעצם מטריקות מראות טרנד מסוים של התנהגות כי הן עושות אגרגציה של הנתונים, מנוע המטריקות לא מציג לך מדידה בודדת לעולם הוא רק אוסף מדידות בדידות.
דוגמא למטריקה מעולם הפיתוח היא כמות השגיאות לפרק זמן של שעה.
מטריקות נכנסות לקטגוריה של ״לדעת האם דברים תקינים״. מטריקה של כמות השגיאות לא תגיד לי איזו שגיאה קרתה לי בשעה 17:58:43 אלא רק תגיד לי שהיתה שגיאה בפרק הזמן הזה.טרייסים (Traces) - פתרון שהחלו להשתמש בו די בשנים האחרונות עם המעבר למיקרו סרוויסים וארכיטקטורה מבוזרת (distributed architecture). נסו לדמיין מצב שבו יש לכם סרוויסים שונים, כל אחד כותב את הלוגים שלו, מתאר מה הוא עושה. קרתה תקלה באחד הסרוויסים, סרוויס א׳, בעקבות מידע לא תקין שהגיע מסרוויס אחר שהפעיל אותו,סרוויס ב׳, כיצד אתם יודעים מה היא הריצה המדויקת של סרוויס ב׳ שיצרה את הנתון הלא תקין?
דרך אחת היא באמצעות זמנים, סרוויס א׳ רץ בשעה 15:00 ולכן נחפש את הריצה התואמת בסרוויס ב׳ בשעה 14:59, נשמע פשוט, אז לא. מה קורה אם סרוויס ב׳ הפעיל את סרוויס א׳ 100 פעמים בשעה 14:59, איך נמצא את הפעם הבעייתית.
הפתרון לכך הוא מזהה ייחודי עבור כל ריצה של המערכת, אותו מזהה עובר בין הקריאות השונות של הסרוויסים וישנה מערכת שיודע לבצע קורלוציה בין הריצות והמזהה, ולהציג לכם את הריצה כולה כולל הלוגים בצורה קוהרנטית.
טרייסים נופלים תחת הקטגוריה של ״היכולת להבין מה הבעיה״.
הבלוג הנוכחי יעסוק בלוגים והבאים בתור יעסקו במטריקות וטרייסים.
CloudWatch
רגע לפני שצוללים ללוגים, כדאי להכיר את השירות שמאגד את כל פתרונות הניטור של AWS והוא נקרא CloudWatch. גשו לקונסול של AWS ורשמו בחלונית החיפוש CloudWatch ובחרו באופציה הראשונה. בתפריט בצד ימין אתם תראו את כל הדרכים ש-AWS מאפשרת לכם לנטר את האפליקציה. הרשימה הזאת מתעדכנת כל הזמן בדרכים ובפונקציות חדשות אבל לב היכולות לא משתנה והוא לוגים, מטריקות וטרייסים.
ועכשיו נגיע למנה העיקרית - לוגים
לוגים
אני מעוניין להכין אפליקציית דמה שתפיק לוגים עבורנו, כדי שנוכל באמת להתנסות בהם. כמובן שאתם מוזמנים השתמש בלוגים שהאפליקציה שלכם מייצרת, אך אם אתם חדשים בתחום, אני מניח שהחשבון שלכם ריק.
אפליקציית דמה
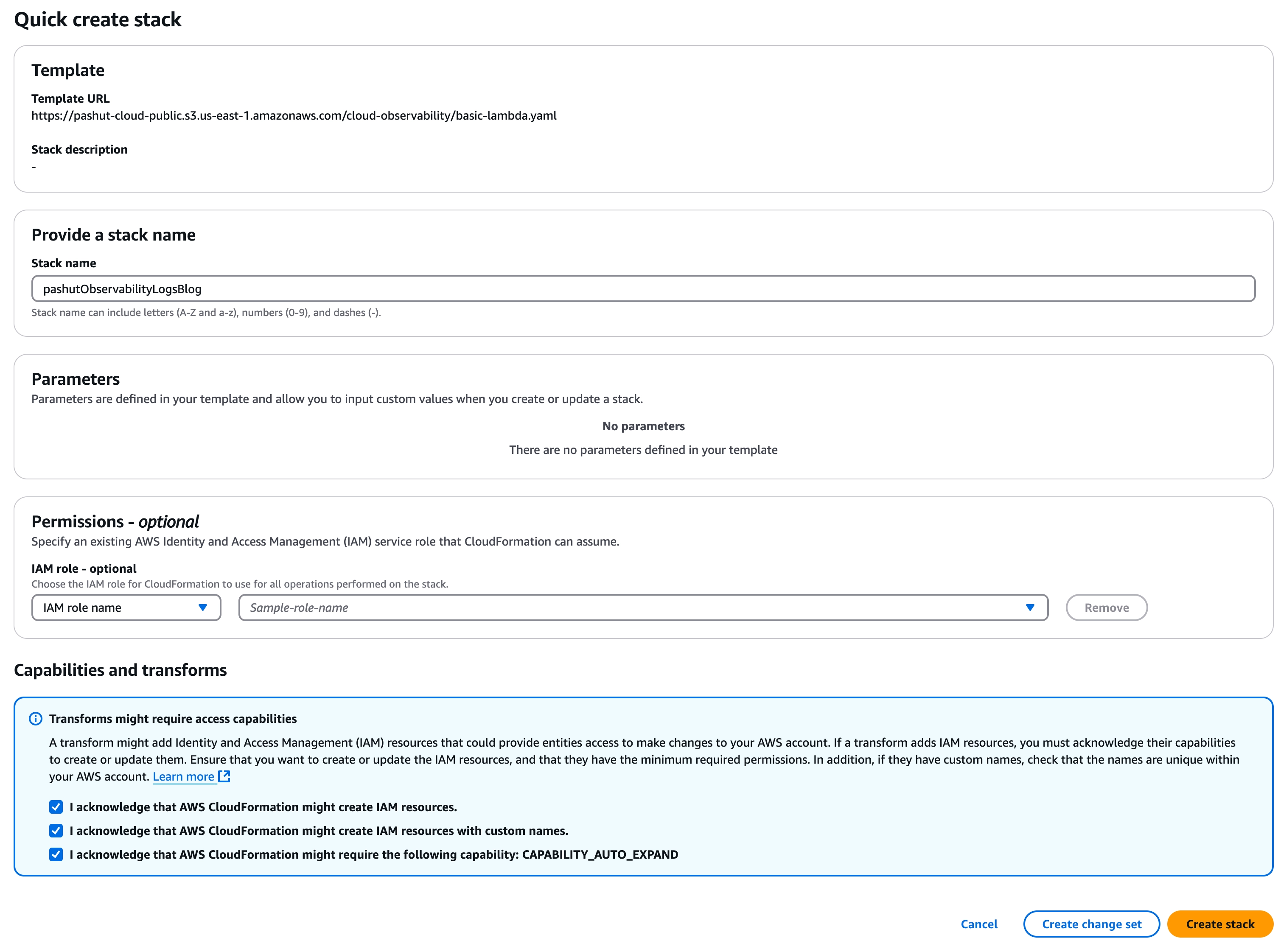
ניתן להתקין את האפלקיציה באמצעות CloudFormation. האפליקציה היא שירות פשוט שמחשב מספר פיבונצ׳י בהתאם לקלט שהוא מקבל. השירות מבוסס למדה שמקבלת שני פרמטרים, האחד הוא המספר שעבורו לחשב את ערך פיבונצ׳י והשני הוא שם המשתמש. בנוסף לשירות עצמו מתווספת למדה נוספת שמסמלצת שימוש רנדומלי בשירות.
לחצו על הקישור הבא, אשרו את דרישות ה-IAM והתקינו. אתם מוזמנים לראות את הקוד של מה שמותקן אצלכם כאן
בסיום ההתקנה, תמצאו שלושה למדות, גשו ללשונית Resources ושם תמצאו קישור שיוביל אותכם ללמדה שמסמלצת שימוש, היא זו שמעניינת אותנו.
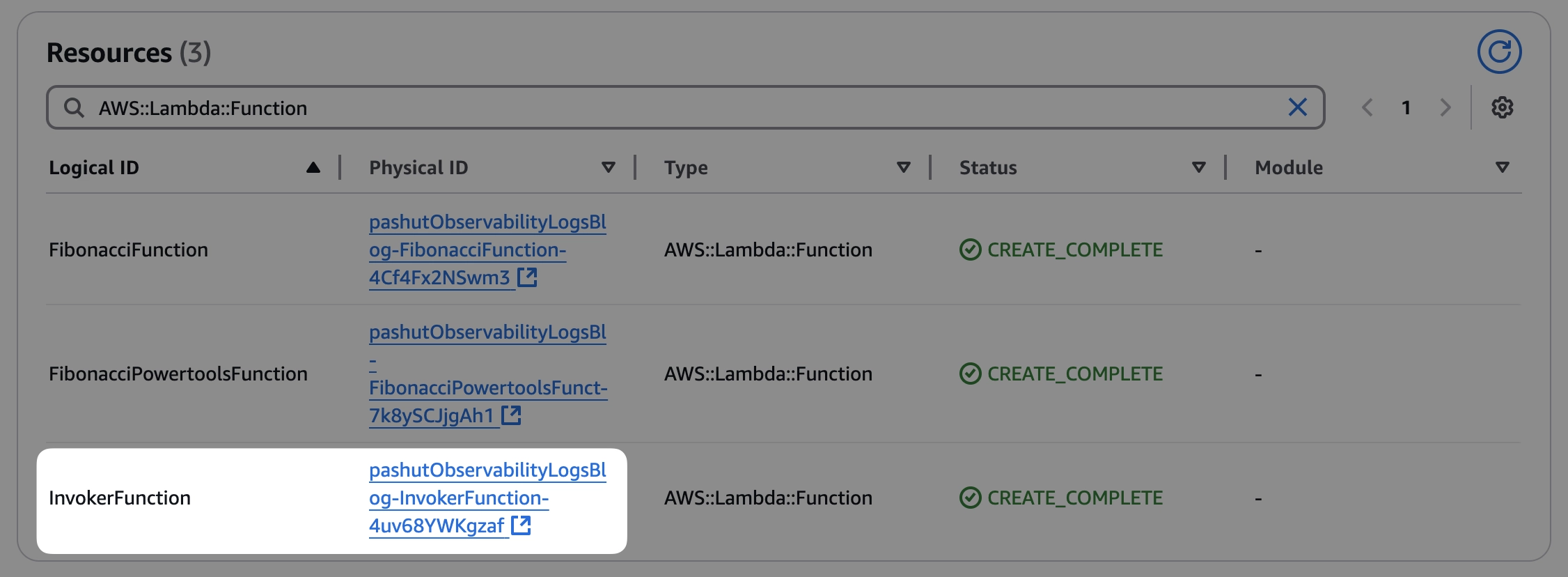
הריצו את הלמדה, הקלט לא משנה, מכיוון שהיא מתעלמת ממנו
ובסיום הריצה אמורה להופיע תוצאה דומה לבאה
1{2 "statusCode": 200,3 "body": "Success"4}אנו נתרכז תחילה בלמדה שנקראית FibonacciFunction ורק בהמשך הבלוג נחזור ללמדה הנוספת שנקראית FibonacciPowertoolsFunction
אנחנו מוכנים 🔥.
Log stream vs Log Group
בואו נמצא את הלוגים שנכתבו, גשו ל-CloudWatch, לחצו על Logs —> Log groups ואז חפשו את שם הלמדה, זה גם השם שהוא ברירת המחדל של ה-Log Group (לוג גרופ).
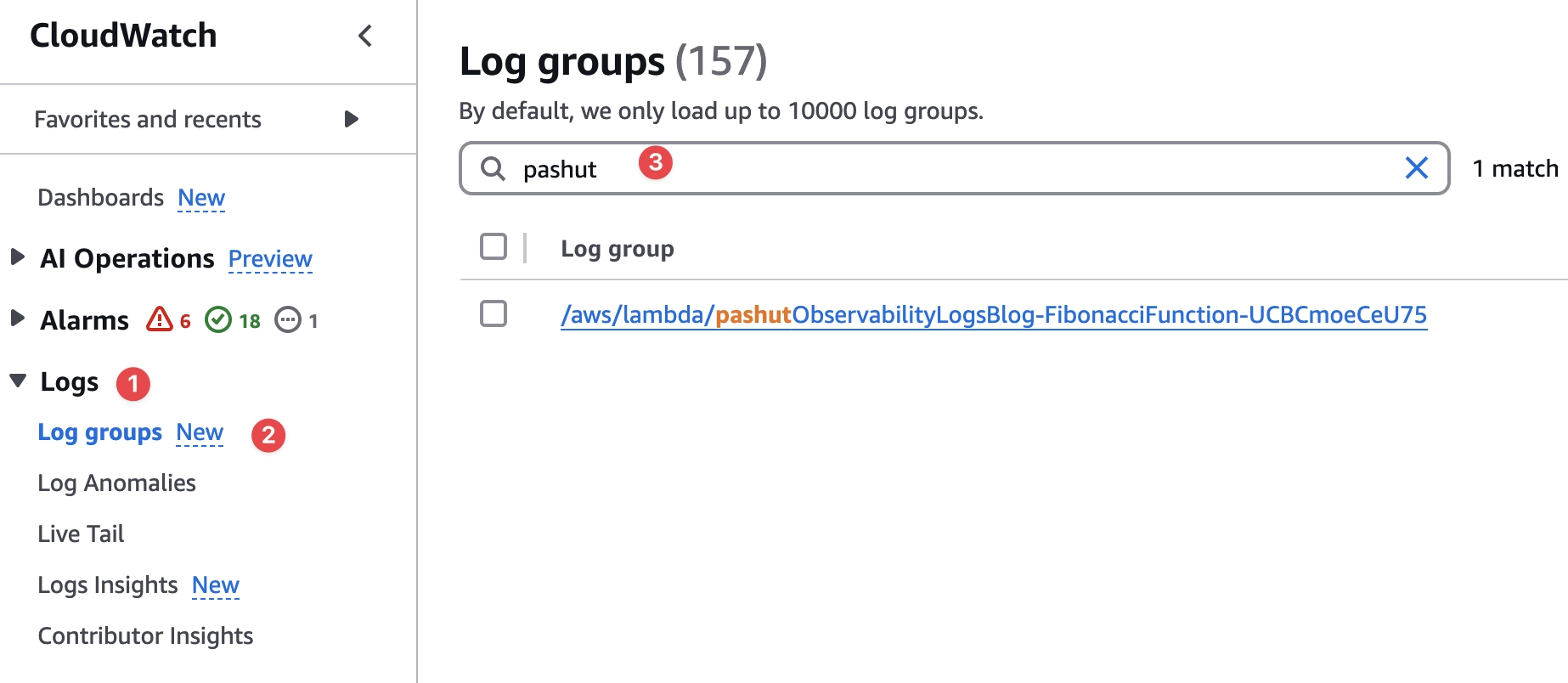
לחצו על הקישור של הלוג גרופ ותופיע בפניכם רשימה של Log streams (לוג סטרים), במקרה שלנו הרשימה תכיל רק לוג סטרים אחד, לחצו עליו ותראו את הלוגים שהלמדה כתבה.
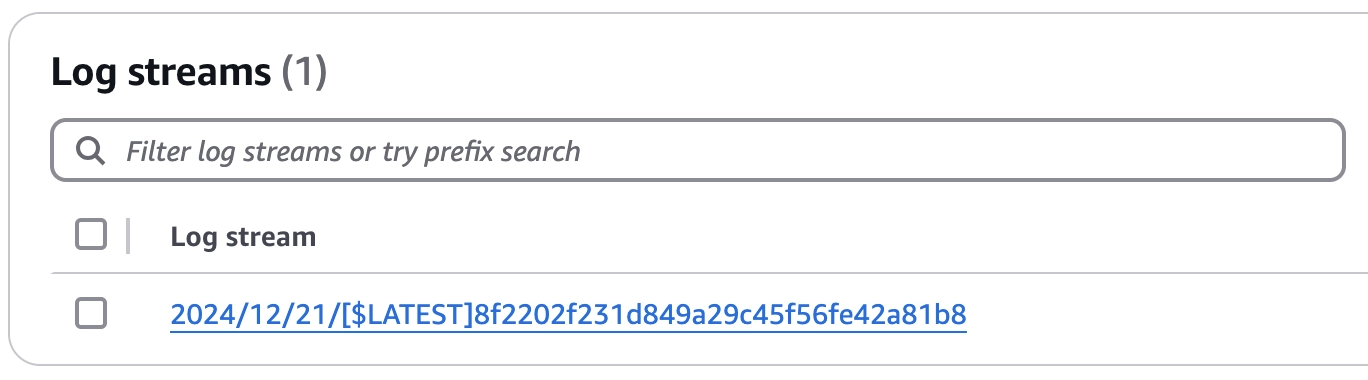
לוג סטרים הוא אוסף לוגים ממקור אחד, בעולם של AWS, מקור יכול להיות קונטיינר בודד של למדה או task של ECS. מה הכוונה בקונטיינר בודד של למדה? כשלמדה רצה בפעם הראשונה, השירות מרים קונטיינר שמשמש את הריצות הבאות, בכל פעם שקוד רץ בקונטיינר הזה, הכל יירשם לאותו לוג סטרים.
שימו לב שיש הגיון בשם שניתן ללוג סטרים, כל לוג סטרים הוא בעל מבנה דומה ל
12024/12/21/[$LATEST]8f2202f231d849a29c45f56fe42a81b8שמכיל את התאריך, את הגירסה של הלמדה ומזהה ייחודי לקונטיינר שרץ. כל מקור של לוגים יעניק שם אחר ללוג סטרים, השם של לוג סטרים של ecs הוא שונה.
לוג גרופ הוא אוסף של לוג סטרימס מאותו מקור לוגי.
אם אתם תריצו את הלמדה לאחר שינוי של הקוד שלה או לאחר שעבר פרק זמן של עשרות דקות אתם תוכלו לראות איך הצטרף לו לוג סטרים נוסף ללוג גרופ.
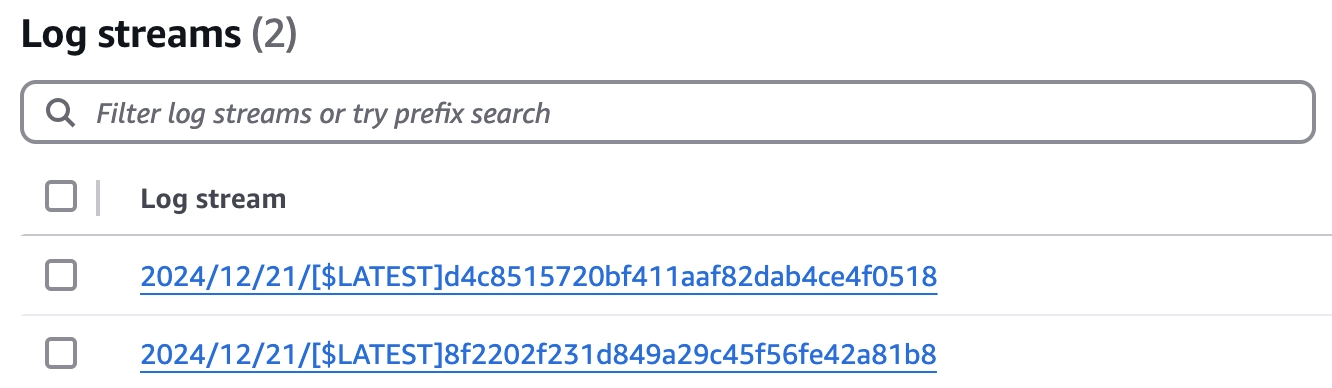
אז למה אנחנו צריכים לוג גרופ? המבנה הלוגי הזה מאפשר לנו להגדיר קונפיגורציה זהה לכל הלוג סטרימס ולהסתכל על התוכן שלהם בצורה הוליסטית, ללא שום קשר למקור של הלוגים ולכמות שלהם. לדוגמא:
כמה זמן לשמור על הלוגים לפני שהם נמחקים, הרי שום דבר הוא לא בחינם.
האם לשלוח את הלוגים למקום נוסף כגון דלי של S3.
זיהוי אנומליות מהלוגים
חיפוש
ועוד…
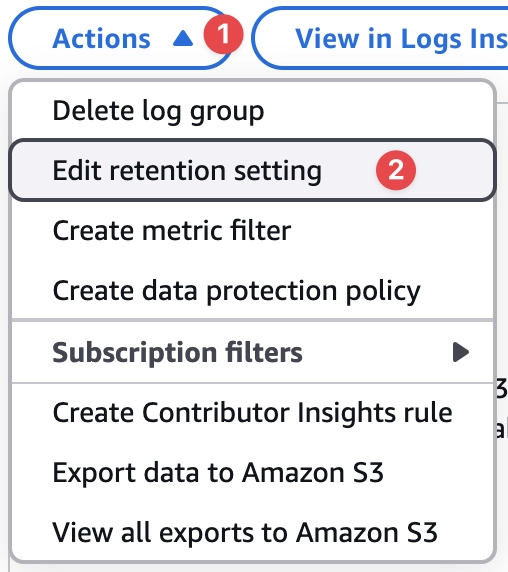
בואו נשנה את פרק הזמן שהלוגים נשמרים, ברירת המחדל כשיוצרים את הלמדה היא לשמור את הלוגים שלה לעד, זה עסק יקר, במיוחד אם הלמדה כותבת המון תוכן. בלוג גרופ של הלמדה שיצרנו, לחצו על Actions ואז Edit retention setting ובחרו יום, שימו לב שהקונפיגורציה השתנה בהתאם תחת ה-Log group details.
לא ניתן להשתמש בלוגים ללא יכולת לחפש בהם, בחלק הבא נלמד על הנושא.
חיפוש
ישנן שיטות שונות לחפש עם יכולות שונות. נתחיל עם הפשוטה לטעמי שהיאfree text seach.
לחצו על Search all log streams, למעלה מופיעה לכם תיבת חיפוש, ניתן לכתוב את הטקסט לחיפוש בשני אופנים:
באמצעות regex - אז צריך להקיף את הטקסט ב-
%טקסט מדויק - מה שכותבים זה מה שנמצא, אך ישנם תווים שאינם מורשים.

כתבו בשורת החיפוש result ולחצו enter, אתם אמורים לראות את השורות (במידה והרצתם את הלמדה יותר מפעם אחת) שמכילות את התוצאה שהלמדה הראתה.
כעת רשמו בשורת החיפוש result: , אתם תקבלו שגיאה, מכיוון ש-: הם תו לא תקין. הקיפו את הטקסט ב-%, רשמו %result:% . החיפוש הזה מאוד מוגבל ביכולותיו מכמה סיבות:
הוא איטי - הוא עובר על הלוגים בצורה סדרתית, אחד אחרי השני.
לא ניתן לחפש במספר לוג גרופס.
regex מוגבל מטבעו בשאילתת החיפוש שאתה יכול לכתוב.
למעשה, אני לא משתמש בסוג החיפוש הזה באופן יום יומי, הפעמים היחידות שאני כן משתמש בו זה כדי לייצר מטריקות או התראות מהלוגים. אולי ניגע בנושא ההתראות בחלק האחרון של סדרת הבלוגים הזאת.
AWS מספקת חיפוש איכותי יותר שמטפל בבעיות הנ״ל. לסוג החיפוש הזה קוראים Logs Insights.
לוג אינסייטס (Logs Insights)
לוג אינסייטס מאפשר לכם לכתוב שאילתא על גבי הלוגים שלכם ובצורה כזאת, לדלות מידע בצורה מתוחכמת יותר. היתרונות המרכזיים שלו הם ניגוד מוחלט ל-free text search:
מהיר, יחסית, הוא יודע לעבור בצורה מקבילית מאחורי הקלעים על הלוגים שלכם ובכך לזרז את מלאכת החיפוש. המהירות תלויה בכמות הלוגים שצריך לסרוק.
ניתן לחפש במספר לוג גרופס יחד.
שאילתות מתוחכמות, מבחינתי זה היתרון של המוצר, לא רק שהוא מאפשר חיפוש מתקדם יותר, הוא גם מסוגל להוציא מידע אגרגטיבי מהלוגים ולהציג לכם מטריקות על הנתונים.
החיסרון הוא שמאבדים את הפשטות, קשה יותר לכתוב עבורו והממשק הוא די בסיסי. דרך אגב, ישנם כלים נוספים לחיפוש לוגים, לא של AWS עם ממשק יותר נוח, אך מטרת הבלוג היא לסקור את הפתרון של AWS.
לגבי הנקודה האחרונה, אגלה לכם סוד, כן חשוב להבין איך השאילתא בנויה ומה ניתן לחפש דרכה, אך אין צורך לזכור את השפה לפרטי פרטים, chat gpt ודומיו (יש גם פתרון פנימי של AWS) יכולים לספק את השאילתא שאתם רוצים.

אז איך ניגשים לוג אינסייטס, מספר דרכים:
ישירות דרך הממשק של CloudWatch
ישירות דרך התפריט דרך הממשק של לוג גרופס

דרך לוג גרופס כשאתם בתוך לוג גרופ

בתוך לוג גרופ גשו ללוג אינסייטס דרך הממשק הראשי. בואו נחקור את מבנה הממשק שלו שהוא די דחוס לטעמי.
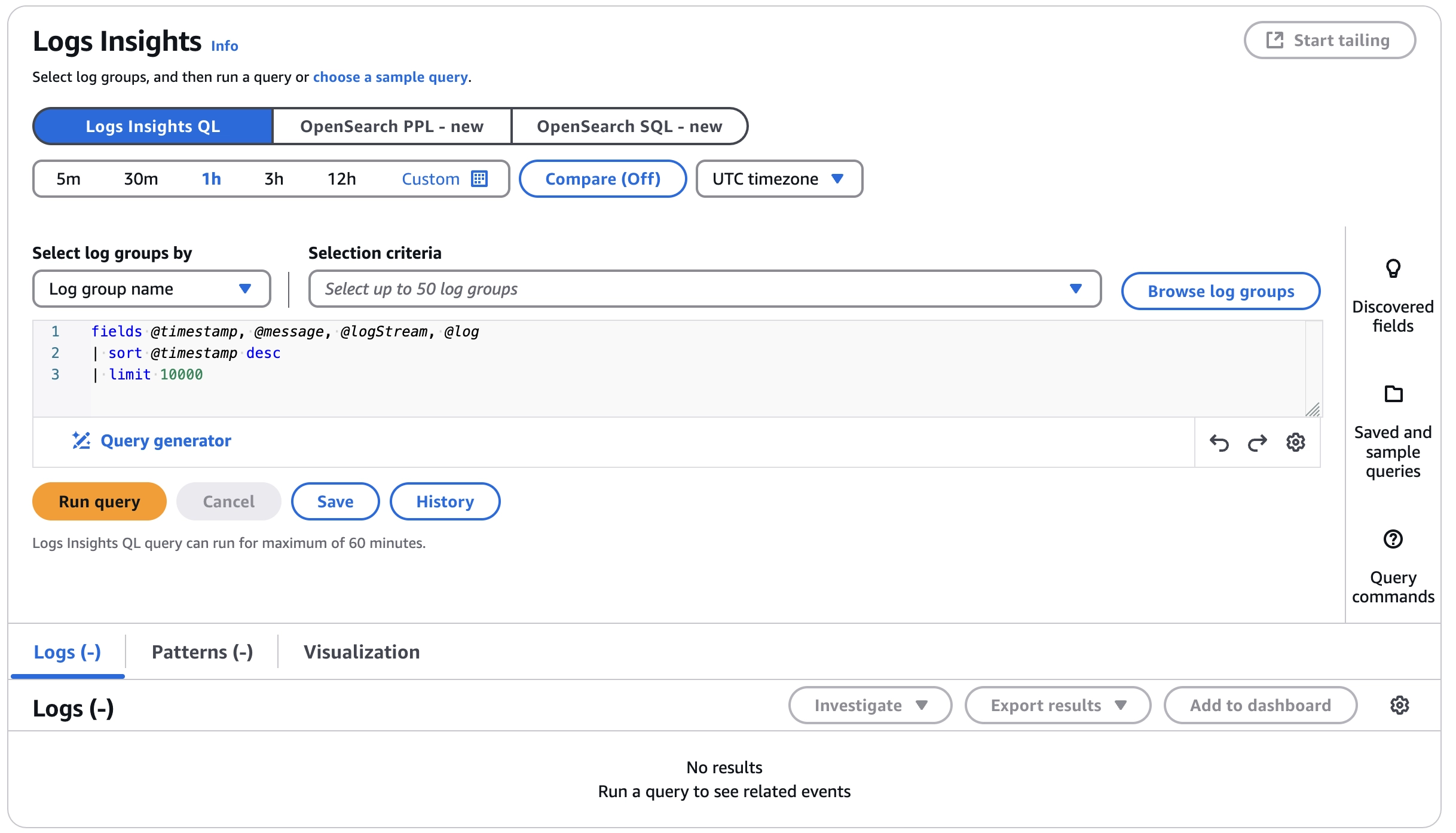
הממשק הראשי הממשק בנוי משלושה חלקים מרכזיים:
קונפיגורציה שמכילה באיזה מנוע חיפוש אנו מעוניינים להשתמש, אנחנו נתרכז בעיקר ב-Logs Insights QL ואת התאריכים שאתה מעוניין לחפש בהם.
חלונית כתיבת שאילתא והרצתה.
תוצאות הריצה.
אנחנו מוכנים להתנסות בכתיבת השאילתות.
שאילתות
השאילתות במנוע מבוססות על pipeline, ישנה פקודה שמבצעת פעולה כלשהי על שורת הלוג ומעבירה את התוצאה לפקודה הבאה, בצורה כזאת, במידה ושורת לוג עוברת את כל הפקודות היא מופיעה בדוח הסופי. חלק מהפקודות משפיעות על האם השורה תופיע בתשובה (פילטור), חלק מהפקודות משפיעות על התצוגה של התשובה הסופית וחלק מהפקודות מבצעות אגרגציה (סטטיסטיקות) של הנתונים על מנת להציג סיכום.
בואו נתחיל עם הפקודה הבסיסית ביותר ונבין את המבנה שלה
1fields @timestamp, @message, @logStream, @log2| sort @timestamp desc3| limit 10000פקודת fields מגדירה אילו שדות אנחנו נראה בתוצאה הסופית. השדות שנבחרו כאן הם שדות מובנים ולא דינמיים ולכן הם מופיעים עם תחילת של @, בהמשך נראה כיצד מוסיפים שדות דינמיים
הפקודה הבאה מופיעה לאחר ה-pipe, זה הסימן | למי שלא מכיר, והיא מגדירה כיצד הנתונים ימוינו בתוצאה הסופית.
והפקודה האחרונה היא הגבלת מספר התוצאות שאנו רוצים לראות.
הפקודה הנ״ל מציגה 1000 שורות לוג ממוינות לפי הזמן והעמודות שיוצגו הן זמן, הודעת הלוג ובאיזה לוג סטרים ההודעה נמצאת.
בחרו את הלוג גרופ שבו אתם מעוניינים לחפש, רשמו pashutObservabilityLogsBlog-FibonacciFunction ותהייה השלמה אוטומטית של הלוג גרופס שנוצרו ע״י אפליקציית הדמו.
בחרו את מסגרת הזמן המתאימה, נניח השעה האחרונה.
לחצו Run query ותוכלו לראות את התוצאות. מעבר לתוצאות הלוגים שנמצאו, שימו לב לגרף שמופיע מעל לתוצאות, הדרף מועיל מאוד במידה ואתם רוצים לראות בצורה ויזואלית באילו הזמנים הלוגים נמצאים, נניח שאתם רוצים לדעת מתי הופיעו שגיאות כלשהן, הגרף הוא ברור יותר להבנה.
כעת נבנה פקודה מתוחכמת יותר.
אפליקציית הדמו מדפיסה שורה דומה לזאת במקרה של קלט שגוי מצד משתמש.
12024-12-21T16:34:51.080Z 9b48490b-23f2-4fd6-9ab5-b7e7a4af1ab0 ERROR User charlie requested Fibonacci of negative number: -1המשתמש bob התלונן בפני שהוא קיבל שגיאה מהמערכת ואני מעוניין למצוא את שורת השגיאה הזאת.
ניתן לבנות משהו דומה לשאילתא הבאה
1fields @timestamp, @message2| filter @message like /User .+ requested Fibonacci of negative number: -[0-9]+/3| parse @message /User (?<username>\S+) requested Fibonacci of negative number: (?<number>-[0-9]+)/4| filter @timestamp <= 1734798891080 and @timestamp >= 17347988910545| filter username like "bob"שורה 1 - מציגה את שדות הזמן וההודעה
שורה 2 - מפלטרת החוצה את כל השורות שאין להן מבנה מסוים, במקרה שלנו, את הודעת השגיאה שאני מחפש.
שורה 3 - שולפת שדות דינמיים מהודעות הלוג המפולטרות שהם השם והמספר שהוא העביר לשירות. זכרו יש כאן תהליך העברת נתונים דרך pipeline, מה שיעבור לכאן עבר פילטור בשורה הקודמת.
שורה 4 - מפלטרים שוב, לפי זמן ולפי שם משתמש. לא חייבים לפלטר כאן לפי זמן, ניתן לפלטר גם לפי הפילטר העליון של מסגרת הזמן. הפלטור העליון יחסוך לכם זמן פילטור וכסף, פילטר בשאילתא לא.
הריצו אותו, אתם אמורים לקבל מספר תשובות, שימו לב שהשדות הדינמיים מצטרפים לשדות שהגדרנו בfields. דרך אגב, אם תורידו את פקדות fields תקבלו רק את השדות הדינמיים בתוצאה הסופית.
בואו ננסה שאילתא אגררטיבית שנותנת לנו מספר. מעניין אותי לדעת כמה משתמשים השתמשו בשירות שלנו בשעה האחרונה ולקבץ ע״פ שם המשתמש.
יש לנו שורת לוג שדומה לזאת
1Event received from userניתן לבנות משהו דומה לשאילתא הבאה
1filter @message like /Event received from user: .*?/2| parse @message /Event received from user: (?<username>\S+) Event:/3| stats count(*) as event_count by username, bin(1h)שורה 1 - קודם כל שימו לב מה השורה הראשונה לא מציגה
fields @timestamp, @messageוזה כי לא מעניין אותנו להציג את הערכים הללו, מעניין אותי להציג שם ומספר. השורה הראשונה מפלטרת הודעות שמכילות את התוכן שייתן לי את המספרים האלו.שורה 2 - שולפים שדה דינמי של שם משתמש.
שורה 3 - זו פקודה חדשה שמבצעת אגרגציה של נתונים, מזכירה קלות שאילתת SQL. היא סופרת את מספר השורות שנותרו, מקבצת ע״פ שם משתמש וחלוקה לזמנים של שעה אחת.
אחד מתוצרי הלוואי משאילתות כאלו היא שלוגס אינסייטס יכולה לייצר לך גרף שפעמים רבות הוא הרבה יותר קל להבנה. לחצו על הלשונית של ויזואליזציה ובחרו בר (bar) כסוג הגרף.

שאלה לקוראים, נניח שאתם מעוניינים לראות כמה פעמים המשתמש dave השתמש בשירות לפי חלוקת זמנים של 10 שניות, כיצד הייתם כותבים את השאילתא? התשובה בסוף הבלוג.
לאן נעלמו שאר הלוגים 🤔
נניח שאתם מחפשים את כל הלוגים שמופיעה בהם שגיאה, נניח משהו בסגנון הבא
1filter @message like /ERROR/פשוט, לא? אבל כעת, אצם מעוניינים לקבל את הלוגים שהם מסביב לאותן שורות עם השגיאות, להבין את הקונטקסט. פעולה פשוטה, אך היא לא אפשרית באמצעות Logs Insights QL, אחדד, זה לא ניתן ע״י שאילתא בודדת. בצעו חיפוש שכזה ותקבלו תשובה דומה לזאת, שימו לב למזהה הייחודי שסימנתי

המזהה הזה הוא מזהה של ריצה, שורות הלוג ששייכות לאותה ריצה, הן בעלות מזהה זהה, חפשו את המזהה הזה שוב באמצעות פילטור
1filter @message like /9b48490b-23f2-4fd6-9ab5-b7e7a4af1ab0/ותמצאו את כל השורות שקשורות לשגיאה הנ״ל. נשאלת השאלה, האם ניתן למצוא את הלוגים של השגיאות באמצעות שאילתא בודדת? התשובה היא כן, וניתן לעשות זאת רק לאחרונה עם הוספת שאילתות מסוג OpenSearch SQL

אני לא אכנס לעומק הסוג הזה של השאילתות, חומר לבלוג אחר בנושא, רק ארשום כאן את השאילתא והסבר קצרצר על הפקודות השונות
1select `@requestId`, `@timestamp`, `@message` from2`/aws/lambda/pashutObservabilityLogsBlog-FibonacciFunction-d8OdP0YN80bw` 3where `@requestId` IN (SELECT distinct `@requestId` FROM `/aws/lambda/pashutObservabilityLogsBlog-FibonacciFunction-d8OdP0YN80bw` where `@message` LIKE '%ERROR%')שורה 1 + 2 - השדות שאנו מחפשים ובאיזה לוג גרופ מתבצע החיפוש.
שורה 3 - תת שאילתא שמביאה את כל השורות שבהן מופיעה שגיאה.
בעצם השאילתא, עושה משהו דומה לשתי הפעולות שעשינו ידנית, חיפוש כל השגיאות והתאמת ה-requestId שהוא המזהה הייחודי.
אחת הבעיות המרכזיות, לטעמי, של צורת החיפוש שהצגתי היא שאין מבנה ברור לשורות הלוג, כל אחד יכול לכתוב את הודעת הלוג במבנה ופורמט כראות עיניו והדבר מקשה על כתיבת השאילתות, במיוחד כשצריך לשלוף שדות בצורה דינמית באמצעות parse. דרך נכונה יותר לעשות זאת היא באמצעות לוגים מובנים או structured logs.
לוגים מובנים
לוגים מובנים, הם לוגים בעל מבנה ברור שחוזר על עצמו בכתיבת הלוגים השונים, לדוגמא בכל לוג שמופיע בו שם משתמש, יש להוסיף את שם המשתמש בסוף שורת הלוג. בצורה כזאת ה-parsing לכל השאילתות יהיה עקבי.
1User requested Fibonacci of negative number: -1. Username: Mosheניתן להמציא מבנה אבל Cloudwatch Logs תומך במבנה שכזה כחלק מהשירות, וכל עוד משתמשים במבנה הזה מקבלים parsing אוטומטי. המבנה שנתמך הוא json.
דרך מאוד פשוטה להוסיף לוגים מובנים הפורמט json בלמדה הוא שימוש ב-Lambda Power Tools, וזו תזכורת עבורי לכתוב בלוג על הספריה הנפלאה הזאת.
איך שימוש בספריה נראה, על רגל אחת
1const { Logger } = require('@aws-lambda-powertools/logger'); 2שורות 1-6 - אתחול הספריה
שורה 9 - הוספת מזהה ייחודי (requestid) לכל שורת לוג
שורה 11 - הדפסת לוג הכוללת הודעה וערכי json שצמודים להודעה.
בדוגא הנ״ל, שורה 11 תודפס בצורה הבאה
1{ 2 "cold_start": false, 3 "function_arn": "arn:aws:lambda:us-east-1:201893381538:function:pashutObservabilityLogsBl-FibonacciPowertoolsFunct-7k8ySCJjgAh1", 4 "function_memory_size": "128", 5 "function_name": "pashutObservabilityLogsBl-FibonacciPowertoolsFunct-7k8ySCJjgAh1", 6 "function_request_id": "8a4244e5-4dac-4862-8ca9-a32806a72c9c", 7 "level": "ERROR", 8 "message": "User requested Fibonacci of negative number", 9 "sampling_rate": 0,10 "service": "fibonacciService",11 "timestamp": "2024-12-28T12:11:57.655Z",12 "xray_trace_id": "1-676feaa6-5c8e24ee2bdaf7d4527efb03",13 "userName": "dave",14 "number": -215}json בכל רמ״ח אבריו.
כיצד הלוג המובנה הזה עוזר לנו? גשו שוב ללוג אינסייטס והפעם בצעו חיפוש בלמדה pashutObservabilityLogsBl-FibonacciPowertoolsFunct .
השדות ב-json מזוהים אוטומטית, רשמו את השאילתא הבאה
1fields level, number, userName, @requestId2| filter userName = "dave" and level = "ERROR"3userName ו-level מזוהים כשדות וניתן לבצע עליהם תשאול ללא צורך להשתמש ב-parse. השאילתא הרבה יותר פשוטה וקריאה, לטעמי.
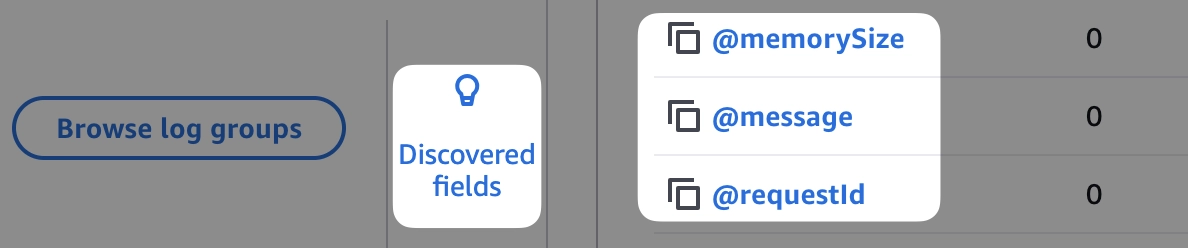
טריק נחמד לזהות את כל השדות שמזוהים אוטומטית ע״י לוגס אינסייטס הוא לחיצה על Discovered fields בתפריט בצד ימין של המסך (הממשק UI פשוט נורא), תוכלו לראות שם את כל השדות שהתווספו באמצעות השימוש בלוגים מובנים.
רגע לפני סיום, אני מעוניין להציף את נושא העלויות ואז נסכם.
עלויות
נושא העלויות הוא נושא חשוב, כמפתחים התוצרים שלנו עולים כסף אמיתי, אלו לא רק מכונות שאנשי ה-IT יצרו עבורנו, הלוגים שאנו מייצרים עולים כסף כי:
הם נשמרים היכן שהוא.
מישהו מעבד אותם, AWS במקרה שלנו, והעיבוד גם עולה כסף.
ולכן חשוב להבין מהי העלות של הלוגים שלנו וכיצד ניתן להורידה. נושא העלויות הוא נושא מורכב והפסקה הזאת לא קרובה לסכם אותו אבל חשוב להכיר וזה רמז לבלוג נוסף עתידי בנושא 😉.
לכל אחד מהנושאים שדנו בהם בבלוג הזה ישנה עלות נפרדת.
שמירה - הלוגים נשמרים, כדי שבעתיד תוכלו לגשת אליהם שוב או כי ישנן דרישות רגולטוריות שדורשות לשמור לוגים לתקופה מסוימת.
עיבוד - הלוגים עוברים עיבוד מסוים, לדוגמא כדי לאפשר לכם חיפוש מהר או כי ישנם מטריקות שמבוססות על הלוגים וכדי להפיק את המטריקות, צריך לעבד את הלוגים.
חיפוש - החיפוש עולה כסף, כי צריך מאחורי הקלעים להרים מכונות שעוברות על הלוגים ומבצעות את החיפוש בפועל.
העלויות שאני רושם כאן הן לאזור n.virginia , לכל אזור בעולם העלויות הן קצת שונות.
שירות | עלות | כיצד לחסוך |
|---|---|---|
שמירה | 0.03$ לכל ג׳גהבייט של נתונים |
|
עיבוד | 0.50$ לכל ג׳גהבייט של נתונים | ע״י שימוש במסלול בשם Infrequent Access, זה מסלול עם מספר מגבלות לדוגמא סוגי שאילתות מסוימות לא נתמכות, אין זיהוי שדות אוטומטי. זה מסלול הגיוני במידה ואתם משתמשים בשירות צד ג׳ כדי לצפות בלוגים שלכם. |
חיפוש | 0.005$ לכל ג׳גהבייט של נתונים שעובר סריקה בחיפוש | להגביל את טווח הזמנים. |
סיכום
בבלוג זה תיארתי את שירות CloudWatch Logs, המאפשר לשמור את הלוגים שלכם ולבצע עליהם חיפוש. עברנו על דרכי השאילתו השונות, מדוע נכון לשמור את הלוגים בצורה מובנית וקינחנו בכסף, שזו תמיד דרך טובה לסיים את היום.
נתראה בבלוג הבא.
תשובה לשאלה
נחזור על השאלה
נניח שאתם מעוניינים לראות כמה פעמים המשתמש dave השתמש בשירות לפי חלוקת זמנים של 10 שניות, כיצד הייתם כותבים את השאילתא?
תשובה:
1filter @message like /Event received from user: .*?/2| parse @message /Event received from user: (?<username>\S+) Event:/3| filter username like "dave"4| stats count(*) as event_count by bin(10s)5
תגובות