

כתיבת לוגים זו דרך מעולה להבין מה האפליקציה שלך עושה במקרה של תקלה, אך מה קורה כשאפליקציה שלך בנויה ממספר סרוויסים שמתקשרים אחד עם השני, כיצד אתה יודע לשייך את הלוגים לפעולה הספיציפית שהמשתמש עשה? אתה צריך לקפוץ, כנראה בין מספר לוג גרופס ולהבין האם הלוג המסויים שייך לפעולה שמשתמש X עשה או משתמש Y עשה. אתה כנראה צריך מזהה ייחודי כלשהו שיאפשר לך להבין ששורת הלוג הספיציפית שייכת לפעולה שהמשתמש עשה. בצורה כזאת ניתן לחפש אחר המזהה הייחודי בכל הלוגים ולמצוא את רצף הפעולות שהמשתמש עשה.
ישנה מורכבות נוספת בהעברת המזהה ייחודי הזה, המזהה הייחודי הזה צריך לדעת לקפץ בין הסרוויסים השונים, לא משנה מהי דרך התקשורת בין הסרווסים, לדוגמא, משתמשים ב-API Gateway או בתור SQS לכל אחד מדרכי התקשורת הללו, ישנה דרך אחרת להעביר את המזהה הייחודי, במיוחד אם אתם מעוניינים לעשות את זה בצורה אגנוסטית לתוכן שעובר.
הלוגים הללו הם הטרייסים (traces), דרך אחת לחשוב על טרייסים היא שהם אוסף של לוגים מובנים עם קורלציה. הם יכולים להגיע מתהליכים, שירותים, מכונות וירטואליות, מרכזי נתונים שונים וכן הלאה. טרייסים הם לא הלוגים הסטנדרטים שאתם כותבים כחלק מהאפליקציה שלכם, אלא ישנה מערכת שיודעת לייצר את הטרייסים האלו עבורכם.
מערכת לייצור טרייסים
כיצד נראית מערכת שיודעת לייצר טרייסים? ננסה לסכם את הפתרון שאנחנו מחפשים ואת הדרישות ממנו:
היכולת לצרף מזהה ייחודי בהתאם לפעולה לכל שורת לוג.
היכולת לצרף מידע נוסף (מטה דטה) לכל שורת לוג שכזאת.
היכולת להעביר את את המזהה הזה בצורה אגנוסטית דרך השירותים השונים שאתה משתמש בהם בתקשרות בין סרוויסים.
היכולת לחפש ולפלטר אחר אותו מזהה ייחודי.
על בסיס הדרישות הללו כל מערכת לייצור טרייסים בנויה לפחות משני קומפוננטות:
SDK - קוד שאתה מטמיע אצלך שבאפליקציה שיודע לזהות את השירותים השונים שאתה מתקשר איתם ולבצע בעצם את הרישום של האינטרקציה איתם. ה-SDK שולח את הטרייסים לשרת.
שרת שיודע לקבל את הטרייסים השונים ויודע להציגם.
נסתכל על הדוגמא הבאה של מספר סרוויסים שמתקשרים ביניהם
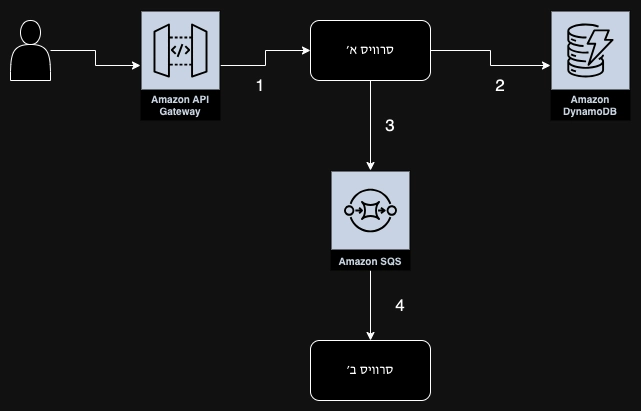
אנו כמשתמשים מטמיעים את ה-SDK בשני הסרוויסים שלנו שמבצעים רישום לכל הפעולות שאנחנו עושים:
קבלת נתונים מ-API Gateway.
כתיבה ל-DynamoDB.
קבל נתונים מ-SQS
וכדומה…
כל תקשורת בין שני סרוויסים שונים תייצר טרייס, הטרייסים יכולים לדמות לתוכן הבא
1{ 2 "traceId": "1-abc123def456", 3 "name": "API Gateway Request", 4 "startTime": "2025-01-04T10:15:30.123Z", 5 "duration": 25, 6 "metadata": { 7 "username": "david.cohen", 8 "httpMethod": "POST", 9 "path": "/api/v1/process"10 }11 }12 {13 "traceId": "1-abc123def456",14 "name": "Service A Processing",15 "startTime": "2025-01-04T10:15:30.148Z",16 "duration": 85,17 "metadata": {18 "username": "david.cohen",19 "serviceVersion": "1.2.3",20 "region": "us-east-1"21 }22 }23 {24 "traceId": "1-abc123def456",25 "name": "DynamoDB Write",26 "startTime": "2025-01-04T10:15:30.233Z",27 "duration": 45,28 "metadata": {29 "username": "david.cohen",30 "tableName": "ProcessingTable",31 "errorCode": "ProvisionedThroughputExceededException",32 "errorMessage": "Rate of requests exceeds provisioned throughput",33 "retryAttempts": 334 }35 }36 {37 "traceId": "1-abc123def456",38 "name": "SQS Message Publish",39 "startTime": "2025-01-04T10:15:30.278Z",40 "duration": 35,41 "metadata": {42 "username": "david.cohen",43 "queueName": "processing-queue",44 "messageId": "msg-789xyz"45 }46 }47 {48 "traceId": "1-abc123def456",49 "name": "Service B Processing",50 "startTime": "2025-01-04T10:15:30.313Z",51 "duration": 45,52 "metadata": {53 "username": "david.cohen",54 "serviceVersion": "2.0.1",55 "region": "us-east-1"56 }57 }שימו לב למזהה הייחודי שעובר כחוט השני בין הטרייסים השונים ולמטא דטה שמאפשר לנו ללמוד על התוכן שעבר בין הסרוויסים השונים. המטא דטה הוא חשוב מאוד, כי רק רישום פעולות שהתבצעו הוא חסר תועלת ללא הנתונים שעברו בין הפעולות הללו, לדוגמא מהטרייסים הנ״ל, אני יכול לדעת מה המקור לתלונה של המשתמש david שהתלונן שהשינויים שהוא עשה לא נשמרו, מסתבר שהיתה תקלה בשמירה ל-DynamoDB.
עד כה הכל היה תיארוטי, הגיע הזמן להתנסות במערכת לייצור טרייסים ב-AWS, אך רגע לפני, בואו נייצר אפליקציית דמו שנוכל להתנסות בה.
אפליקציית דמו
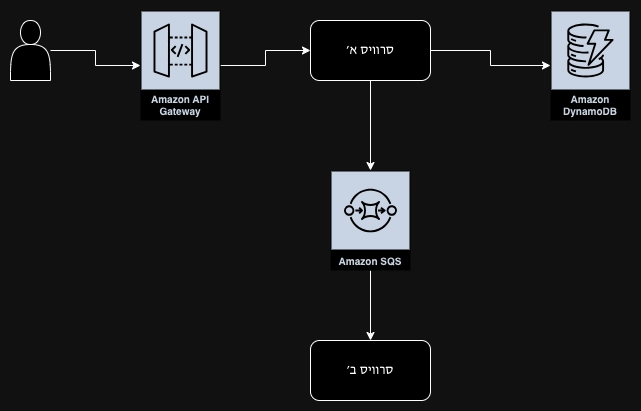
אפליקציית הדמו מורכבת משני סרוויסים:
סרוויס א׳ - פתוח לעולם באמצעות API Gateway, כל בקשה אליו מכילה את שם המשתמש שביצע את הבקשה, אנחנו מעשירים את המטא דטא של הטרייסים עם שם המשתמש הזה. הסרוויס מבצע כתיבה לטבלת DynamoDB ומידי פעם נכשל בכתיבה, אני נמצא את הכשלון ואת סיבותיו באמצעות הטרייסים. בסיום הכתיבה לדטה בייס, נשלחת הודעה לתור SQS שלצידו השני מאזין סרוויס ב׳.
סרוויס ב׳ - מקבל את ההודעות מתור ה-SQS ומבצע עליהן פעולה כלשהי לפי בקשת המשתמש.
ישנה למדה אשר מסמלצת משתמש ואותה נריץ על מנת לייצר לנו ריצות סינטטיות.
ניתן להתקין את האפליקציה אצלכם בסביבת הענן על ידי לחיצה על הקישור הבא, אשרו את דרישות ה-IAM והתקינו. אתם מוזמנים לראות את הקוד של מה שמותקן אצלכם כאן.
בסיום ההתקנה, גשו ללשונית Resources ושם תמצאו קישור שיוביל אותכם ללמדה שמסמלצת שימוש, היא זו שמעניינת אותנו.
הריצו את הלמדה, הקלט לא משנה, מכיוון שהיא מתעלמת ממנו
ובסיום הריצה אמורה להופיע תוצאה דומה לבאה
1{ 2 "statusCode": 200, 3 "body": { 4 "message": "Test completed", 5 "results": [ 6 { 7 "statusCode": 200, 8 "data": { 9 "message": "Data processed successfully",10 "timestamp": "2025-01-04T15:44:49.723Z"11 ...התוצאה מסכמת את תוצאות הריצה, אילו קריאות נכשלו ואילו לא. כעת הגיע הזמן לראות את הטרייסים.
שימוש ב-xray
אנו נשתמש בשירות שנקרא xray כמערכת שמייצרת ומציגה עבורנו את הטרייסים. השירות מורכב משלושה חלקים שונים:
SDK שאותו את מטמיע אצלך בקוד ומייצר את הטרייסים.
xray daemon הוא שירות מקומי שרץ בסביבה שאותה את מנטר (למדה או ECS Task), מקבל את הטרייסים השונים, מבצע עליהם אגרגציה ומחליט על בסיס פרמטרים שונים האם לשלוח אותם לשרת. ה-sdk לא ישלח את הטרייסים ישירות לשרת אלא רק ל- daemon.
xray service - השירות של AWS שמקבל טרייסים, עושה עיבוד עליהם ומאפשר להציג אוותם בצורה ויזואלית.
הטמעת xray בקוד
ההטמעה ב-AWS באה לידי ביטוי בשני מקומות: SDK והפעלת הdaemon.
במידה ואתם משתמשים בלמדה, ניתן להפעיל את ה-daemon ע״י הדלקה שלו, ממש plug and play.
וכמובן ניתן לעשות זאת באמצעות AWS SAM ע״י הוספת תכונה בשם Tracing להגדרת הלמדה.
1ServiceAFunction:2 Type: AWS::Serverless::Function3 Properties:4 Tracing: Activeבמידה ואתם משתמשים בecs ההמלצה היא להגדיר daemon עבור כל task definition, מתוך מטרה של הקטנת עומס על daemon אחד מרכזי.
ההטמעה בקוד גם היא משתנה בהתאם לסוג השירות שאתם משתמשים, שוב בלמדה זה יחסית plug and plug, אנחנו נשתמש ב-lambda power tools(LPT) שעוטף את ה-xray sdk ונשתמש באנוטציה כדי להפעיל את ה-sdk.
1Properties:2 Tracing: Active3 # ...4 Layers:5 - !Sub arn:aws:lambda:${AWS::Region}:017000801446:layer:AWSLambdaPowertoolsPythonV3-python313-x86_64:5בקוד הנ״ל, אנחנו מגדירים lambda layer שמכילה את ה-power tools ובקוד עצמו, שהוא דוגמא לפייתון, אך הוא דומה במהותו גם ב-LPT שהן עבור שפות אחרות
1from aws_lambda_powertools import Tracer 2from aws_lambda_powertools import Logger 3אנו מייצרים אובייקט טרייסר ומשתמשים באנוטציה כדי לעטוף את ה-handler.
באפליקציות יותר סטנדרטיות, זה קצת יותר מורכב, אתם תצטרכו להשתמש בxray sdk ישירות, לדוגמא באפליקציית flask:
1from flask import * 2from flask_cors import CORS 3# ... 4from aws_xray_sdk.core import xray_recorder 5from aws_xray_sdk.ext.flask.middleware import XRayMiddleware 6הבנו כיצד אפליקציית הדמו הטמיעה xray, הגיע הזמן לראות את התוצאות לאחר ריצת הדמה.
תצוגה ויזואלית
מפה
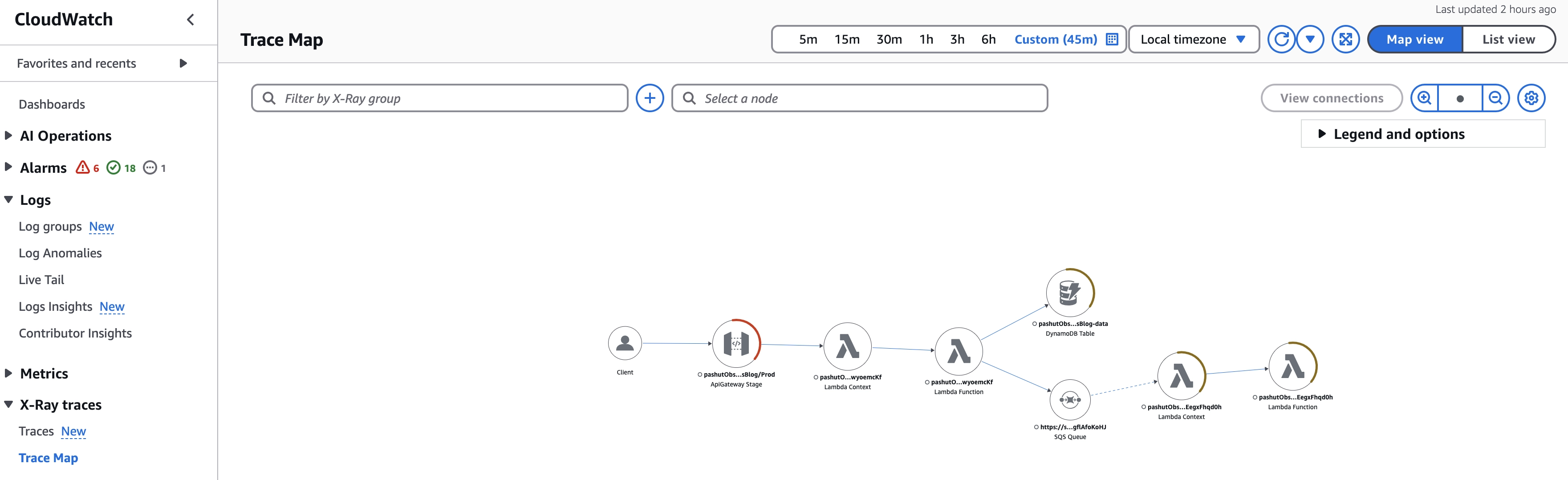
אחת מנקודות החוזקה של xray היא המפה (Trace map) שמופיעה בתפריט בצד שמאל תחת xray traces. זו תצוגה שלא תוכלו לקבל מהלוגים כפי שהם ואחד היתרונות המרכזיים של שימוש בxray וטרייסים. המפה מציגה את הארכיטקטורה שלכם, את כל הסרוויסים השונים, החיבור ביניהם ובמבט אחד ניתן להבין האם ישנן תקלות, סוג התקלות והיכן. המפה היא אגרגציה של כל הטרייסים שנשלחו, שימו לב, זו לא קריאה בודדת, אלא צירוף של כל הקריאות יחד.
המפה מבצעת רישום של כל הטרייסים, סרוויסים שנמחקו או חיבורים שלא היו נכונים לזמנם יכולים עדין להופיע, במידה ובחרתם מסגרת זמן שמכילה אותם. קחו את זה בחשבון כשאתם מסתכלים במפה.
התצוגה הויזואלית תואמת לארכיטקטורה שסרטטנו בתחילת הבלוג
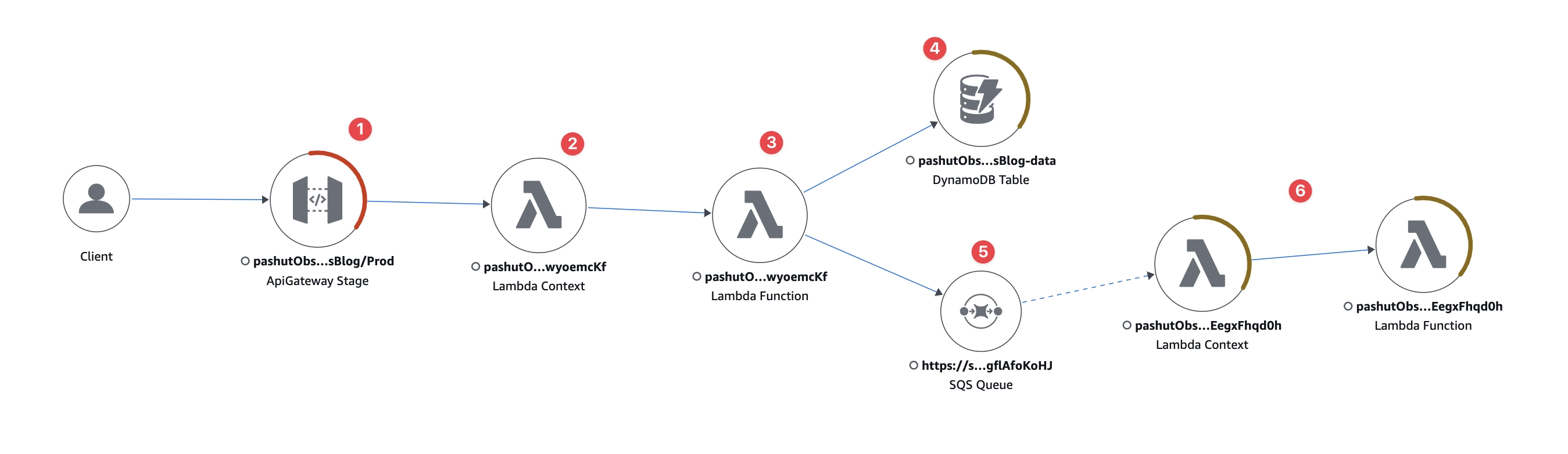
זהו שירות ה-api gateway שמהווה את נקודת הכניסה לשרות שלנו. שימו לב שיש עליו סימון אדום, משמעות הדבר שהיו שגיאות שהוחזרו לקורא, גודל הסימון האדום גם מעיד על כמות השגיאות בפרק הזמן הזה (1/3).
ה-api gateway מטריג את שירות הלמדה, שימוב לב שישנה כאם הפרדה בין השירות לבין הקוד שלנו, השירות מבצע אוסף פעולות כגון אתחול הקוד, xray מגדיר את זה כחלק מהארכיטקטורה שאנו רואים.
הקוד שלנו שרץ. זה קצת מבלבל לטעמי, כי השירות הוא שירות אחד ולכן היה נכון יותר לחבר את שני הצמתים(nodes) לכדי צומת אחד.
קריאה ל-dynamodb, גם כן ישנו סימון שמזהה כשלון (4xx). מהסתכלות ראשונית אפשר אולי להסיק שהתקלות שה-api gateway מחזיר, קשורות בצורה כלשהי לתקלות של dynamodb.
כתיבת הודעה לתוך sqs
ה-sqs מטריג למדה שקוראת ממנו את ההודעה. שימו לב שהקו בין 5 ל-6 הוא מקווקו שמשמעותו היא הפעלה אסינכרונית של השירות השני.
לחצו על אחד הצמתים, לדוגמא api gateway, תוכלו לראות אגרגציה בתחתית המסך של המטריקות שקושורת לאותו צומת.
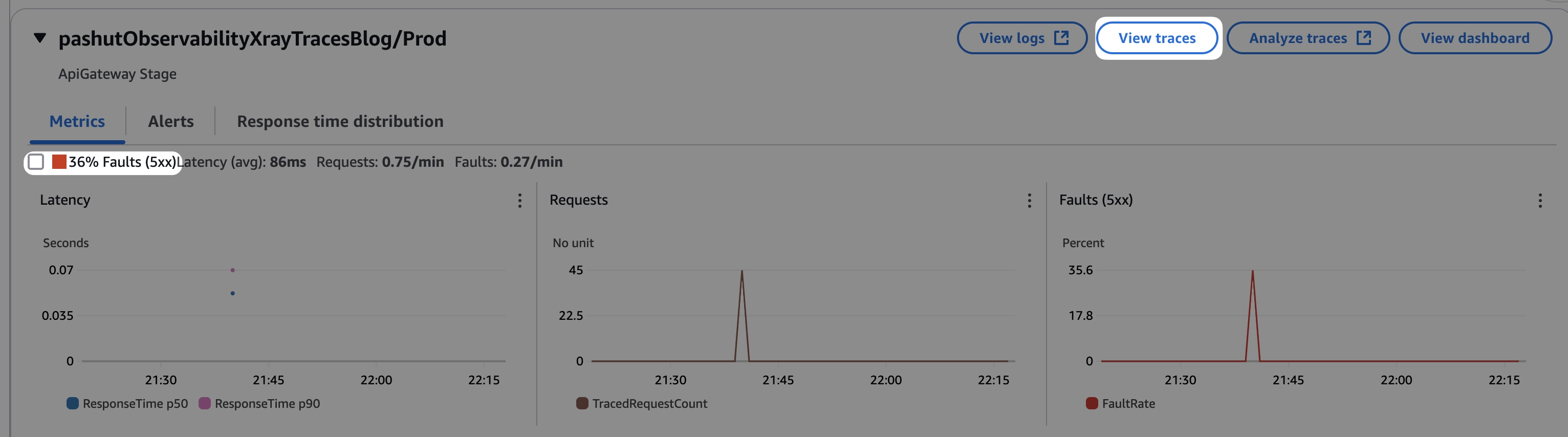
ניתן לראות כאן אחוזי השגיאות והכי חשוב, מכאן ניתן להגיע בקלות לאותן שגיאות. סמנו את הערך 36% ולחצו על View filtered traces, ואז תתקבל רשימה של הריצות הספיציפיות שנכשלו. חזרו חזרה והפעם הסירו את סימון השגיאות, לחצו על View traces ולחצו על טרייס אחד ללא שגיאה, כזה שה-trace status שלו הוא OK.

תצוגת טרייס בודדת
ברגע שבחרנו טרייס בודד, הגענו לריצה ספיציפית, וזאת בניגוד לתצוגה המפה.
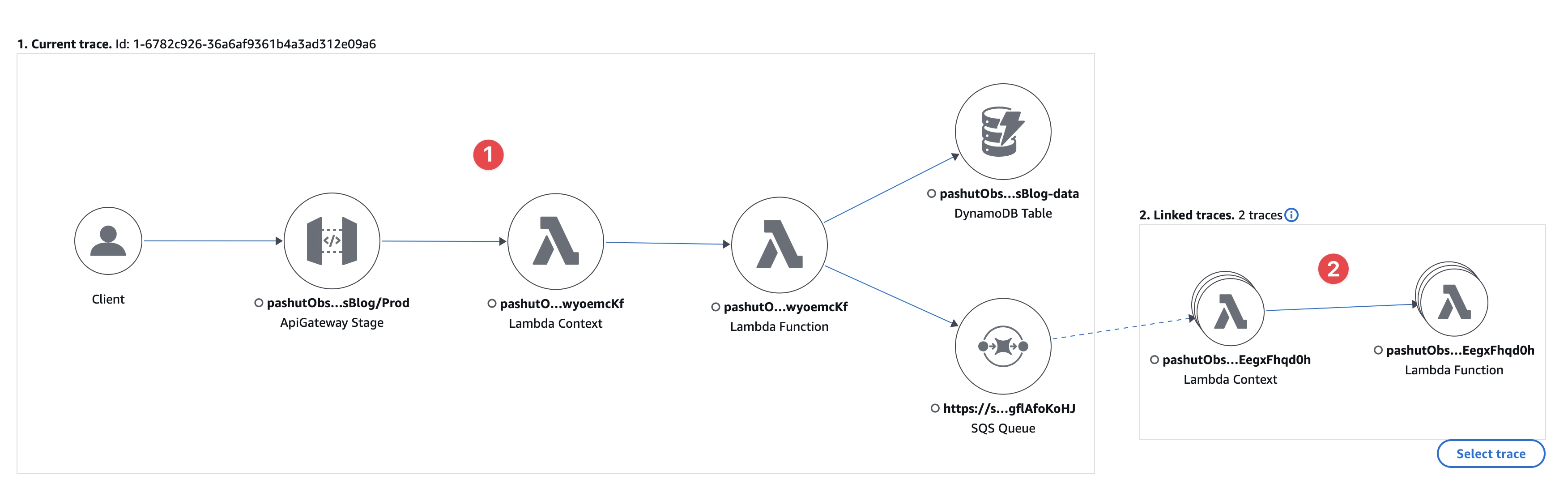
המפה של הטרייס הבודד למעשה מציגה שלנו שני טרייסים, טרייס של השירות הראשון, מסומן ב-1 וטרייס של השירות השני שמסומן ב-2. בעצם החלוקה הזאת מציגה את כוחו האמיתי של מנגנון הטרייסים, יש כאן שני שירותים שונים, בריצה בודדת, ש-xray יודע באמצעות מזהה משותף שרץ מאחורי הקלעים לחבר אותם לכדי תצוגה אחת.
נרד לתחתית המסך ונראה טיימליין (timeline) שהוא מציג את זמני הריצה של הקומפוננטות השונות בתוך הטרייס, זו תצוגה אחרת למפה שאנו רואים למעלה והיא מאפשרת לנו לבדוק זמנים ולשפר ביצועים.
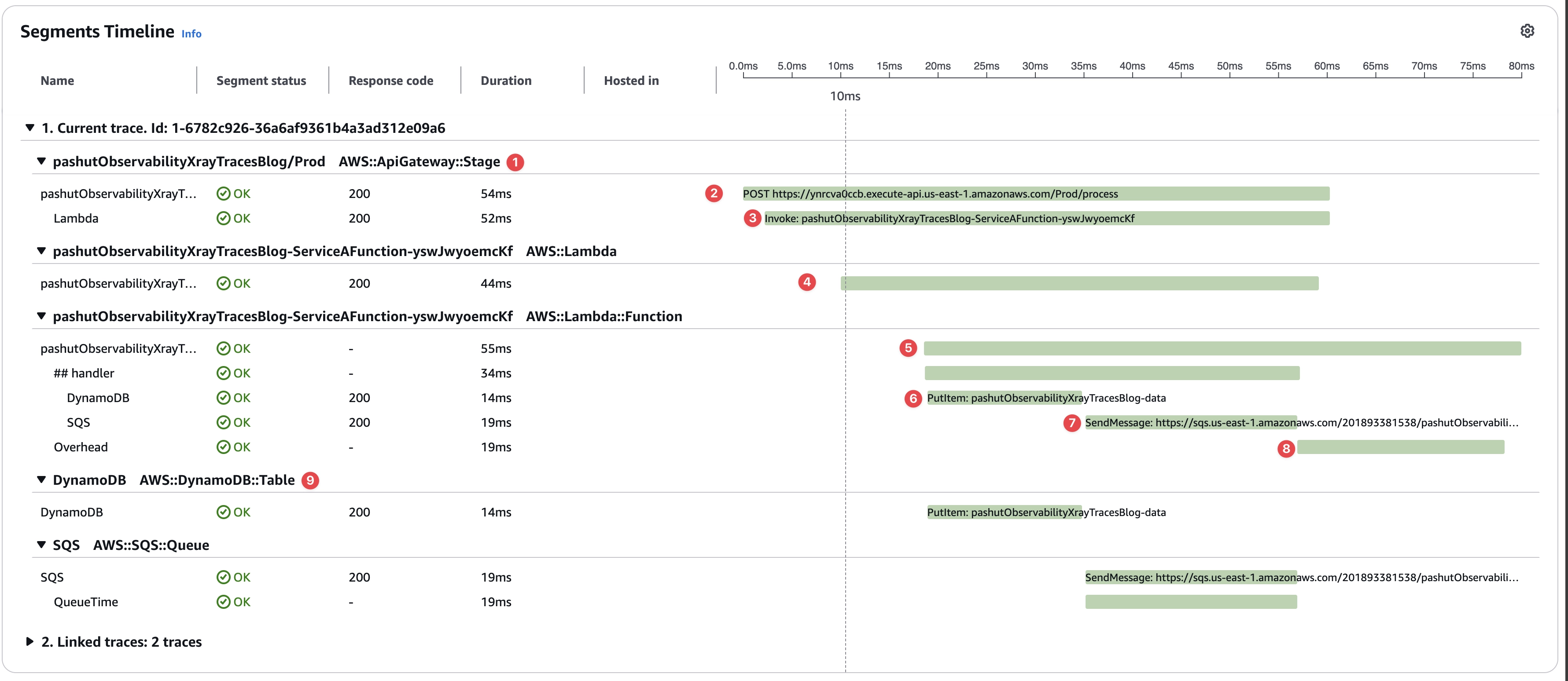
שימו לב שהחלקים השונים בתוך הטרייס נקראים סגמנטים, סגמנטים, זו הדרך שלנו ב-xray לעשות תתי חלוקות לקריאה כולה למטרות תצוגה ופילטור, ישtrace id אחד שבתוכו יש המון סגמנטים.
ניתן לייצר סגמנטים בקוד לדוגמא ע״י שימוש באנוטציה של tracer.capture_method כך שבכל פעם שתקרא מתודה מסוימת בקוד, יווצר סגמנט.
1@tracer.capture_method2def collect_payment(charge_id: str) -> str:כל הסגמנטים שאנו רואים בתמונה למעלה נוצרו אוטומטית עברונו ע״י ה-LPT.
בואו נעבור על המספרים השונים ונבין אותם, יש הגיון בסדר הוא ע״פ סדר הקריאה והסגמנטים השונים מכילים אחד את השני:
זו קריאת ה-api, אורכה כאורך זמן הריצה של הלמדה.
זה הפירוט, זו למעשה קריאת POST
מאחורי קלעים api gateway מטריג למדה, יש עלות לעבודת ההטרגה, וזו הסיבה שיש הפרש של מספר מילי שניות בין תחילת הפעולה ל-invoke. עלות לדוגמא היא טעינת שם הלמדה שצריך להטריג מזיכרון cache כלשהו.
שירות הלמדה עולה לאוויר, שוב שימו לב לפער בזמנים, יש עלות לכך, לוקחת זמן לבצע קריאה פנימית בתוך AWS להטריג את השירות ולגרום לו לעלות, לדוגמא IAM verification.
הקוד שלנו מתחיל לרוץ, אחרי שסביבת הלמדה עלתה לאוויר. שוב יש עלות גם לזה.
מבצעים קריאת DynamoDB.
מבצעים קריאת SQS.
הקוד שלנו סיים לרוץ (אפשר גם לראות את זה בכך שה-api gateway מסיים את הטיימליין שלו גם כן) אך יש תהליך overhead של עצירת extension (על כך בפוסטים בעתיד), עצירת המכונה הוירטואלית ועוד.
במידה והיו לנו סרוויסים נוספים עם סגמנטים בהם, היינו רואים את פרטיהם כאן, במקרה שלנו מציגים את הקריאה ל-dynamodb ול-sqs שאין בהם סגמנטים נוספים.
במידה ונמשיך עוד לרדת בתצוגת המסך, נוכל לראות את הלוגים השונים שקשורים לריצה.
העשרת טרייס בתוכן
כפי שראינו עד כה,טרייס, יחד עם הסגמנטים השונים יודע להציג לי את הקריאות השונות שבוצעו לשירותים השונים, זמניהם, לחבר את השירותים השונים לכדי תצוגה אחת של קריאה בודדת, אך פעמים רבות ארצה להעשיר את הטרייס בתוכן כגון שם שם המשתמש שביצע את הפעולה או איזו שגיאה קרתה בדיוק או אילו ערכים הפונקציה קבלה כשהיא החלה לרוץ. ההעשרה תאפשר לנו לחפש אחר הטרייסים הללו בצורה קלה, לדוגמא, מצאו לי את כל הפעמים שהמשתמש אור נתקל בשגיאה ספציפית במערכת.
אז ישנן שתי סוגי העשרות:
העשרה מאונדקסת שמאפשרת לי לחפש אחריה - נקראית annotation.
העשרה לא מאונדקסת שלא ניתן לחפש אחריה - נקראית metadata.
נשאלת השאלה למה לא לאנדקס את הכל, מכיוון שלא כל סוגי פריטי המידע ניתנים לאינדוקס, ניתן לאנדקס רק מספרים, ערכים בוליאניים ומחרוזות, כמו כן ישנה מגבה של כמה ערכים ניתן לאנדקס לטרייס בודד והערך הוא 50.
במידה ואתם משתמשים ב-LPT ניתן בקלות להשתמש באנוטציות ומטה דטה
1from aws_lambda_powertools import Tracer 2from aws_lambda_powertools import Logger 3כמו כן LPT יוסיף אוטומטית מטה דטה של התשובה (response) של הלמדה שלכם ועוד כל מיני דברי מתיקה שנראה אותם אוטוטו. במידה ואתם לא משתמשים ב-LPT, אז צריך להשתמש בSDK ישירות.
ניתן לראות את הפרטים שהעשרנו ע״י לחיצה על אחד הצמתים או הסגמנטים. במקרה שלנו, אנו העשרנו את הסגמנט של ריצת הקוד שלנו. לחצו עליו.
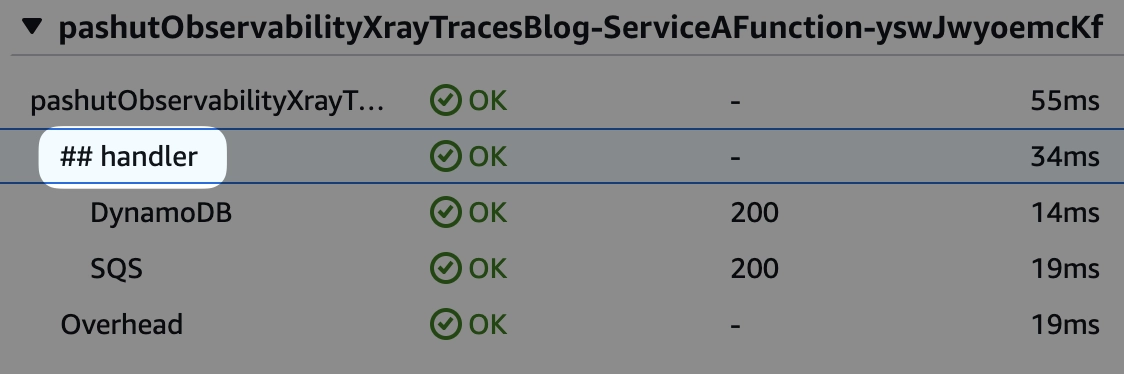
בצד שמאל תקפוץ לכם לשונית עם פרטים על הסגמנט. גשו ללשונית אנוטציות.
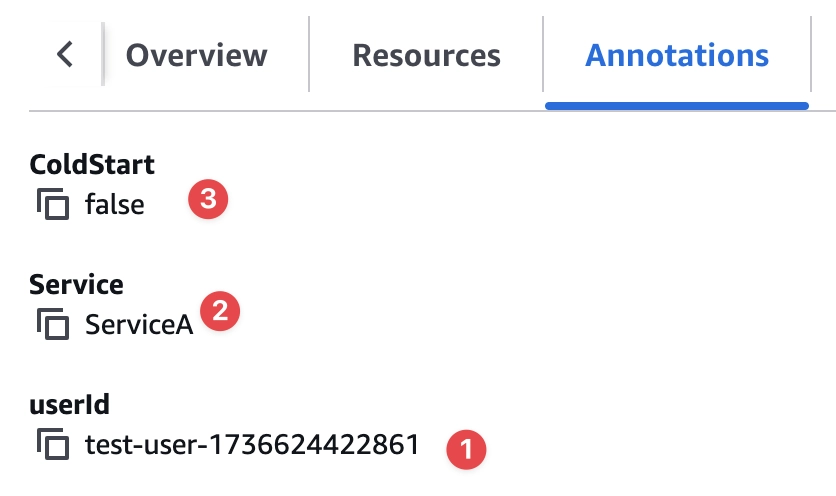
userId זו אנוטציה שהוספנו באמצעות הקוד, והשתיים האחרות התווספו אוטומטית ע״י LPT.
בואו נשתמש באנוטציות וביכולות הפילטור אל xray על מנת לחפש את השגיאות שלנו ונבין את הסיבה לשגיאה.
פילטור
משה מתלונן כל הזמן על תקלות במערכת, אחת שהפעולות שהוא שולח לביצוע לא תמיד מתבצעות, למרות תשובה שמעידה על הצלחה, קרי קבלת 200.
להזכירכם, האפליקציה בנויה משני סרוויסים:
ServiceA - הסרוויס שמחובר ל-API Gateway והוא זה שמחזיר 500 למשתמש.
ServiceB - בהתאם לבקשת המשתמש מבצע את הפעולה שהמשתמש ביקש.
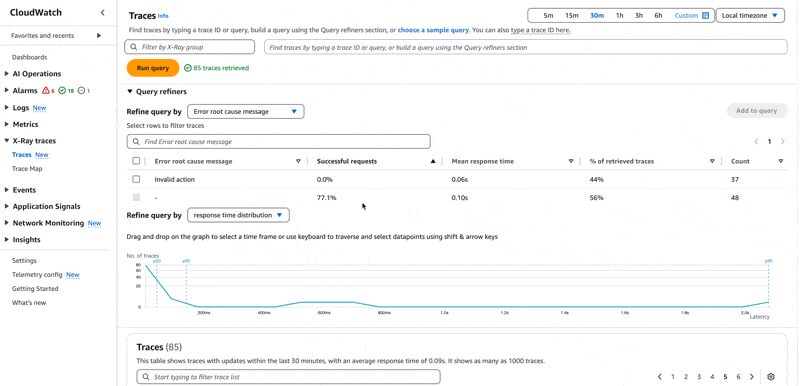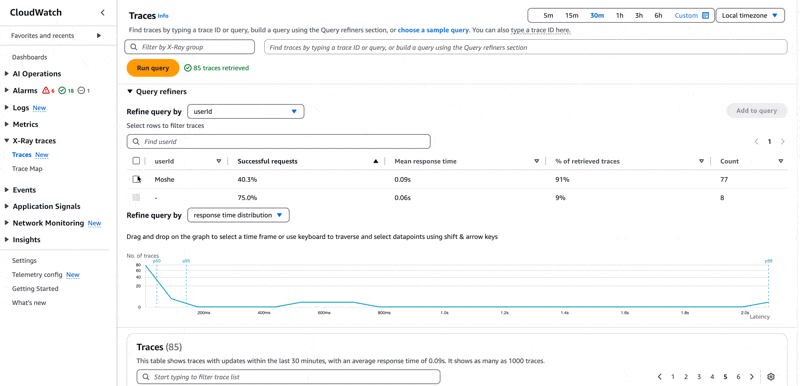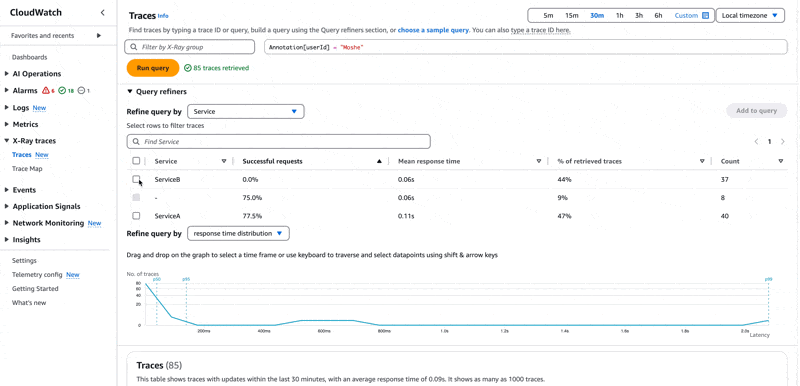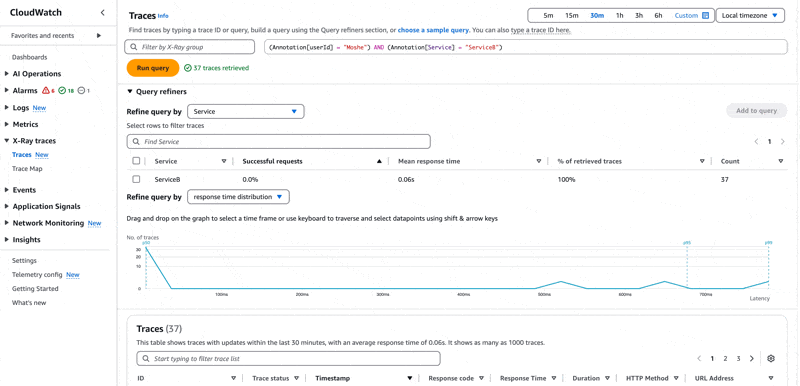
ניגש לעמוד הטרייסים (1), עמוד הטרייסים מאפשר לנו לפלטר את כל הטרייסים ולהציג אותם כרשימה אחת ארוכה.
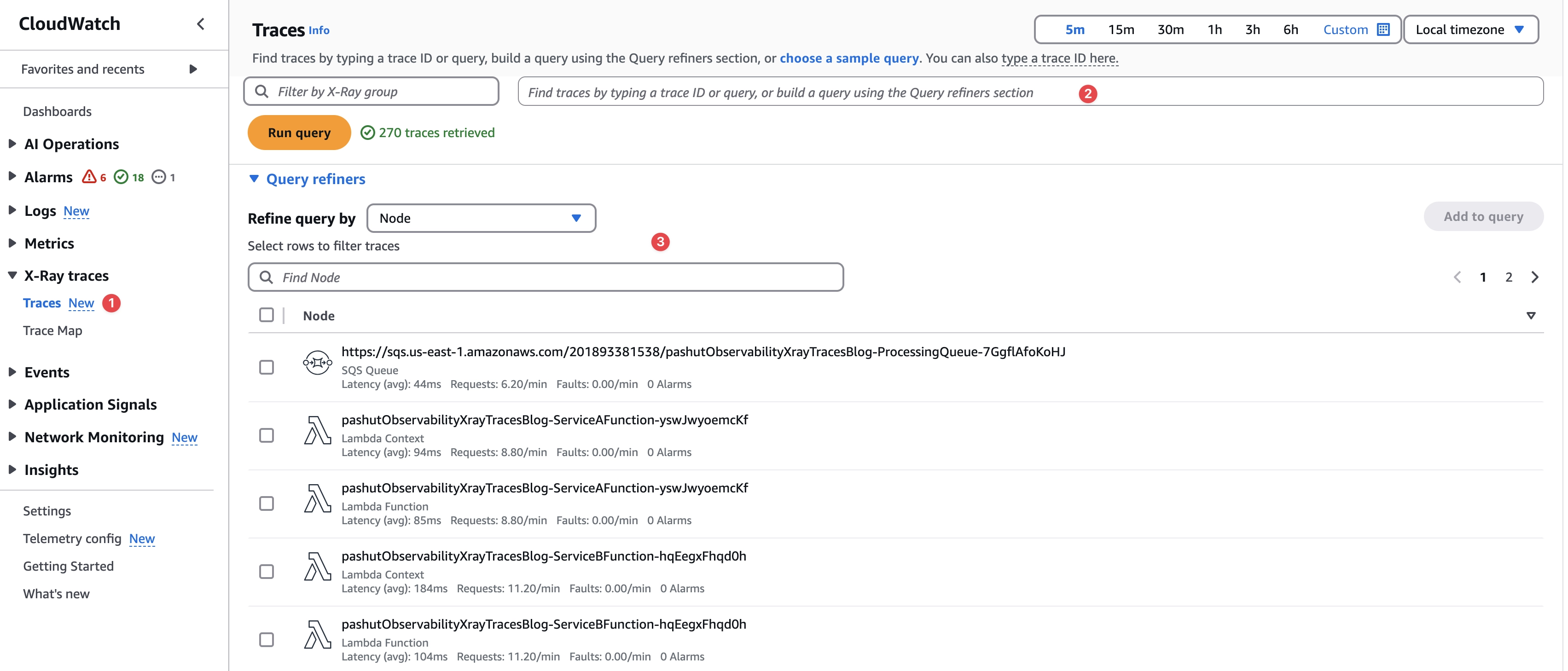
ניתן לרשום שאילתת פילטור בתיבת הטקסט העליונה (2) (נתעלם כרגע מ-XRay Group).
אנו מחפשים את המשתמש משה, בסרוויס ServiceB עם שגיאה. ניתן לכתוב את השאילתא בתיבת הטקסט העליונה בצורה הבאה
1annotation.userId="Moshe" 2and annotation.Service="ServiceB" 3and service(){error=true}שורה 1 - מחפשים אנוטציה עם הערך משה.
שורה 2 - מחפשים ב-ServiceB שגם אותו הגדרתי כאנוטציה בצורה אוטומטית ע״י הגדרת משתנה סביבה בשם POWERTOOLS_SERVICE_NAME שה-Lambda Power Tools תומך בו.
שורה 3 - בסרוויס שאני מחפש בו יש שגיאה.
הריצו את השאילתא ואתם תקבלו רשימה של טרייסים שתואמים לה. ניתן להיעזר גם ב-query refiners ב-3 על מנת לכתוב את השאילתא, xray מצליח לזהות את האנוטציות השונות, כך שאתם לא צריכים לזכור. הדבר גם מאפשר לכם לכתוב שאילתות מורכבות עם מאפיינים נוספים, ללא הצורך לזכור את מבנה השאילתא.
לחצו על אחת התוצאות, תפתח לכם תצוגת הטרייס הבודד, גשו לטיימליין ולחצו על הסגמנט של ה-handler
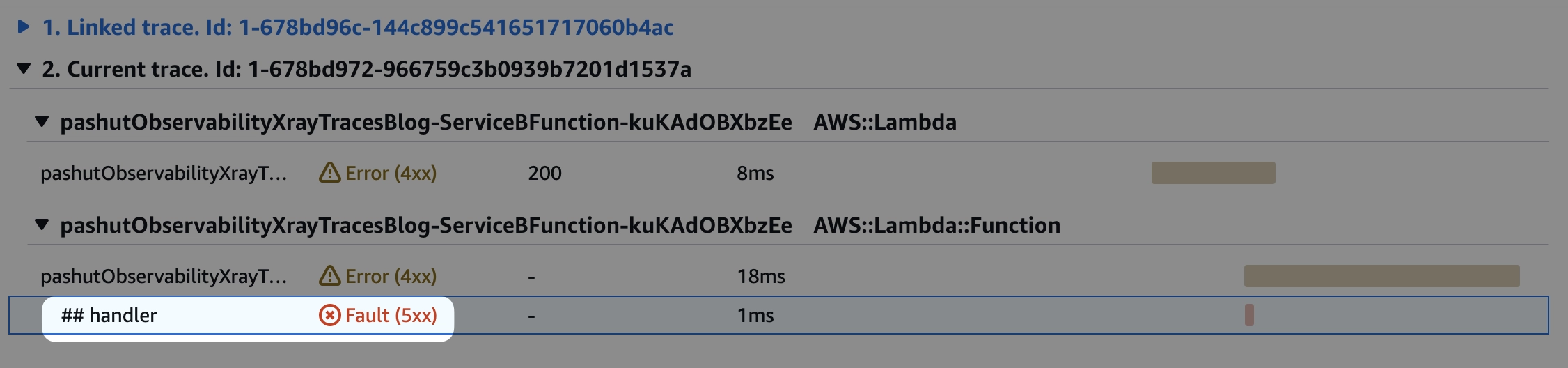
וגשו ללשונית של ה-exception, ואכן שם כתובה שגיאה המעידה על הבעיה, הפעולה שנשלחה אינה תקינה.
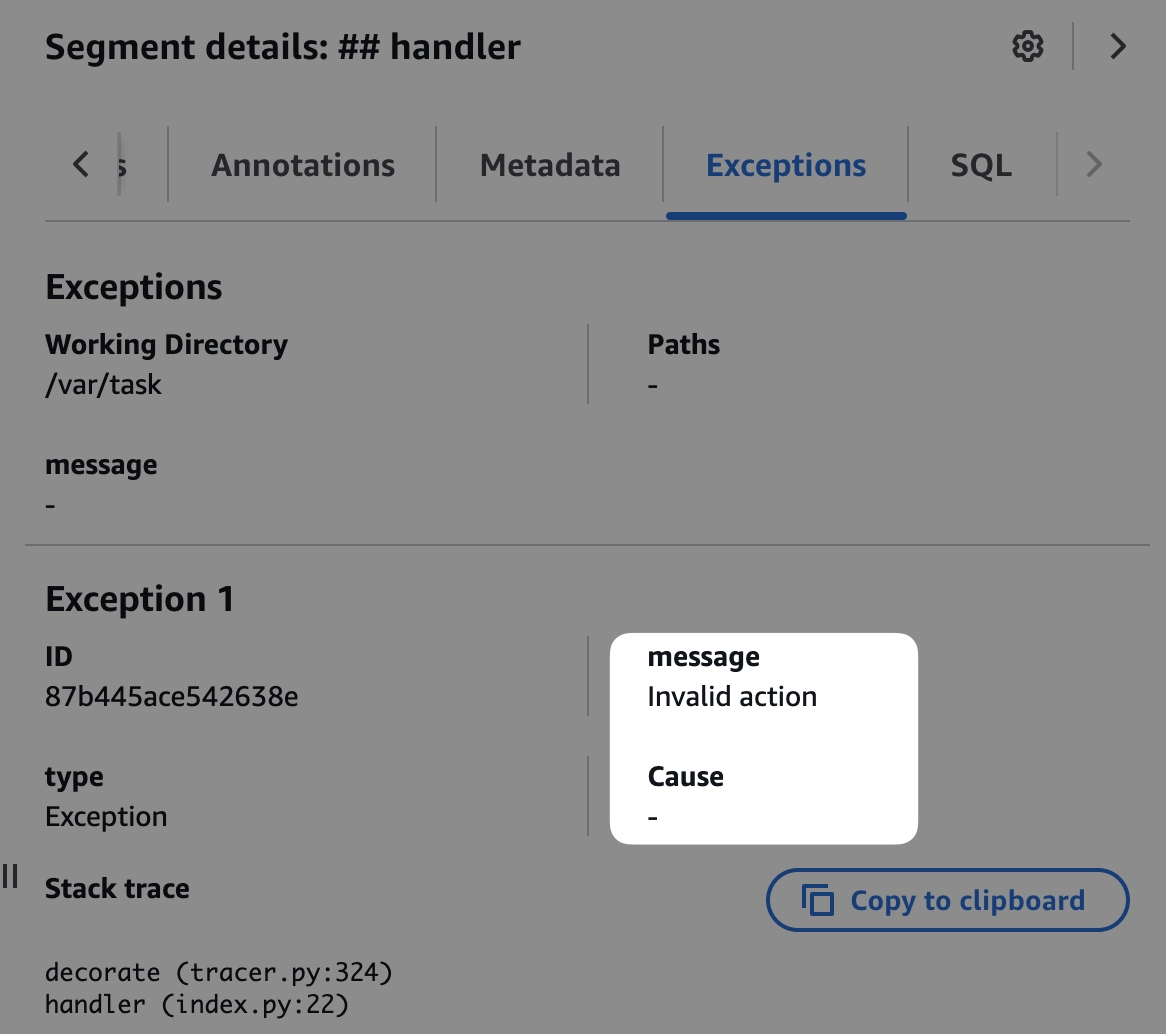
נשאלת השאלה איזו פעולה אינה תקינה, ואם נרד ללוגים בתחתית המסך, אכן נראה את סיבת השגיאה, נשלחה פעולה בשם Ran במקום Run. החיבור בין טרייסים ללוגים הוא מאוד משמעותי, ופעמים רבות בלוגים ייכתב מידע רב ועשיר יותר ממה שנכתב בטרייס עצמו. הטרייסים עוזרים לחבר בין סרווסים שונים ולהבין מי קרא למי ועם מה, אך אילו פעולות ספיציפיות הסרוויס עשה, זה כנראה יתגלה באמצעות לוגים.
כעת השאלה שנשאלת, מדוע הפעולה היא Ran, מה המקור שלה. הסתכלו בלשונית ה-metadata, אנו מבצעים שם רישום של התוכן שהגיע ללמדה.
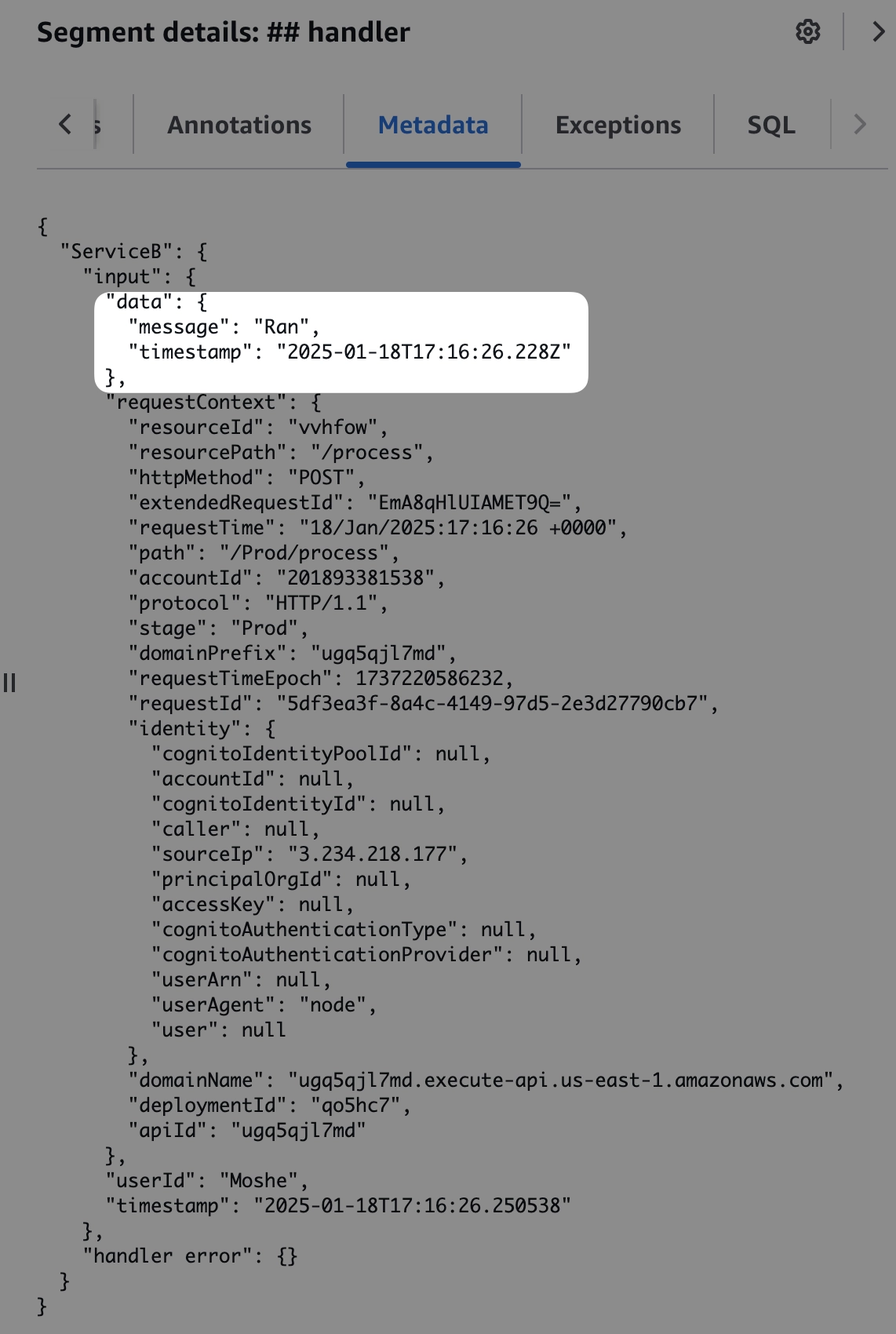
זו פיסת מידע משמעותית, משמעותה שהבעיה היא לא בסרוויס הנוכחי, הוא מקבל קלט לא תקין. נלך צעד אחד אחורה, לסרוויס שמכניס הודעה לתור, נסתכל רגע על ה-metadata ונראה שאכן הסרוויס הזה מכניס תוכן לא תוכן, הבעיה נובעת בסרוויס הזה.
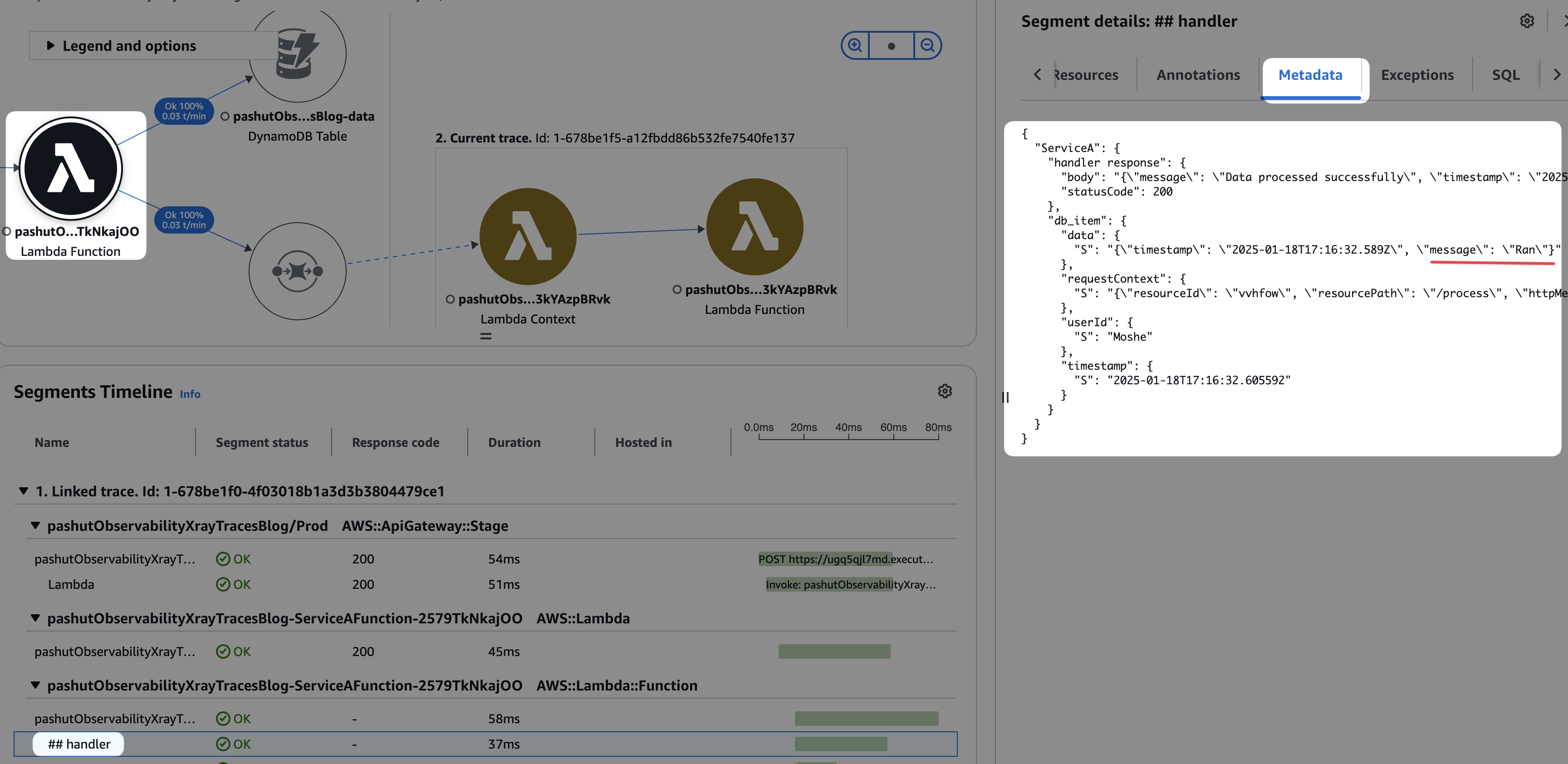
זו נקודת חוזק נוספת של טרייסים, היכולת לעלות במעלה השרשרת על מנת למצוא את מקור הבעיה לשגיאה ה - root cause.
Xray Groups
ישנה יכולת פילטור נוספת שיכולה להועיל מאוד בהתראה על מציאת בעיות. לפעמים נרצה לייצר התראה בכל פעם שטרייס עם מאפיינים מסויימים מופיע. לדוגמא, משה הוא לקוח VIP (משה הוא תמיד לקוח VIP) ובמידה וקרתה תקלה אצלו, אתם מעוניינים לקבל התראה.
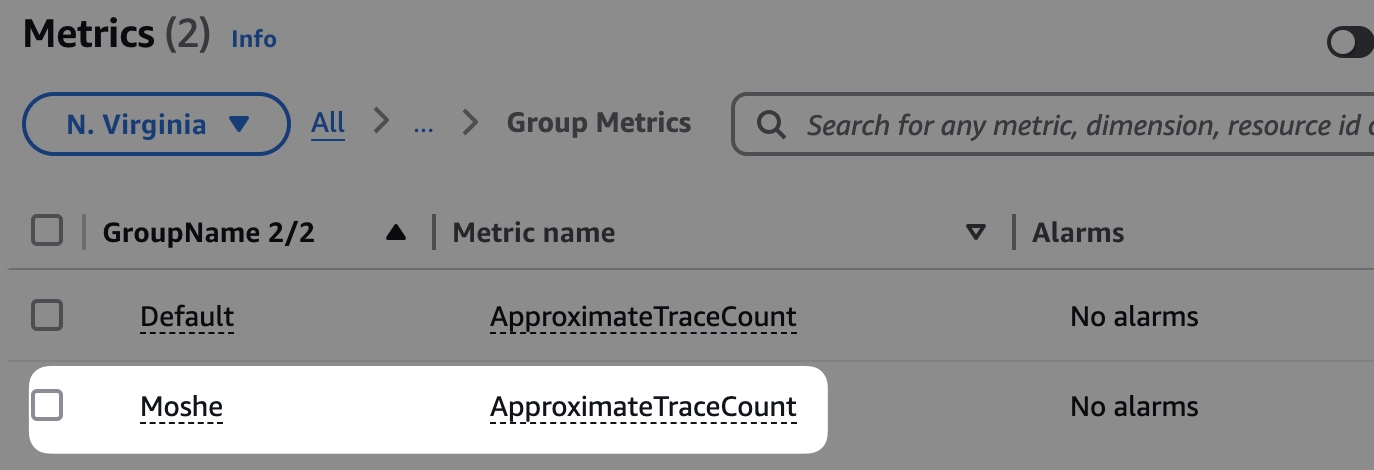
ניתן לייצר xray group באמצעות שאילתא, בכל פעם שיווצר xray group, אז AWS ייצרו מטריקה שסופרת את מספר הפעמים שטרייס כזה הגיע למערכת וניתן לייצר התראה על המטריקה הזאת.
כיצד מייצרים group חדש. ניגשים לתצוגת המפה, לוחצים על סימון ה-+, נותנים שם, וכותבים את השאילתא, לאחר היצירה, תוכלו למצוא את המטריקה תחת CloudWatch Metrics.
לא ניתן לסיים את הפוסט על טרייסינג בלי להזכיר את otel.
Otel (Open Telemetry)
Xray הוא שירות שבאמצעות ה-SDK שהוא מספק ניתן לייצר טרייסים, שירות ה-Xray, צורך את אותם טרייסים ויודע להציגם על מפה, ומאפשר לחפש אותם בהתאם לקריטריונים שונים. אחד החסרונות של Xray שניתן לצרוך את הטרייסים שלו אך ורק ב-AWS, במידה והיתה הסכמה על כיצד טרייסים אמורים להראות, היה ניתן לצרוך אותם גם בשירותים אחרים, חיצוניים ל-AWS ואולי אפילו טובים יותר. לפני מספר שנים, יצא לאור פריימוורק open source בשם Open Telemtry, שיודע לייצר טרייסים שכלי ניטור אחרים מסוגלים לקרוא ולהציג, כלים חינמיים כגון פרומתאוס או ייגר או כאלו שהם גם בתשלום כגון דטהדוג או לומיגו.
ניתן להשתמש ב-Otel גם ב-AWS, תופתעו לגלות, או שלא, ש-Xray יודע לעבד טרייסים שהם מסוג Otel. נשאלת השאלה למה להשתמש ב-Otel במידה ויש לנו את Xray. מספר סיבות:
אתם לא מעוניינים להשתמש ב-Xray, ישנם כלים אחרים שאתם חושבים שהם טובים יותר. Otel הפך להיות הסטנדרט בתחום הזה ולכן ישנו סיכוי שהכלים שתשמשו בהם תומכים ב-Otel.
אתם זקוקים ל-SDK שיידע לייצר עבורכם טרייסים, ישנן שפות פיתוח שלא נתמכות ע״י Xray, לדוגמא C או Rust.
מאוד קל להטמעה, במיוחד בסביבות למדה, אין צורך לכתוב שורת קוד אחת.
ישנם יתרונות רבים, אך גם מספר חסרונות:
ההשפעה שלו על Cold Start היא משמעותית יחסית ל-Xray.
מורכב יותר לשימוש, המון יכולות שבאות לידי ביטוי גם במורכבות ההטמעה.
רמות שונות של איכות, תלוי שפה. לדוגמא הטרייסר של NodeJS לא יודע לייצר מפה איכותית כמו Xray SDK.
הטמעה בלמדה
ההטמעה היא די פשוטה, מוסיפים Layer ומשתנה סביבה ומקבלים טרייסים אוטומטית. באמת פשוט.
1ServiceBFunction: 2 Type: AWS::Serverless::Function 3 Properties: 4 Runtime: python3.13 5 Tracing: Active 6 Handler: index.handler 7 Environment: 8 Variables: 9 AWS_LAMBDA_EXEC_WRAPPER: /opt/otel-instrument10 Layers:11 - !Sub arn:aws:lambda:${AWS::Region}:901920570463:layer:aws-otel-python-amd64-ver-1-29-0:1ניתן לראות דוגמא מלאה כאן
סיכום
כתיבת לוגים זו דרך מעולה להבין מה האפליקציה שלך עושה במקרה של תקלה, אך מה קורה כשהאפליקציה שלך בנויה ממספר סרוויסים שמתקשרים אחד עם השני? במערכות מודרניות שמורכבות מהמון שירותים, עלינו להעביר מזהה ייחודי בין השירותים השונים כדי לאפשר מעקב אחר הפעולה. הטרייסים מאפשרים בדיוק את זה - איסוף מובנה של לוגים עם קורלציה, שיכולים להגיע מתהליכים, שירותים ומכונות שונות. AWS X-Ray הוא פתרון שמאפשר לנו לבצע טרייסינג, לחפש ולפלטר אחר טרייסים, להעשיר אותם במטא-דאטא, ולקבל תצוגה ויזואלית של זרימת המידע במערכת. בנוסף, קיים גם Open Telemetry כפתרון קוד פתוח שמתאים למקרים בהם רוצים גמישות או תמיכה בשפות נוספות.
תגובות