

ממש חם מהתנור, לפני כמספר ימים, AWS, הוציאו פיצ׳ר מיוחד ללמדה שנותן לה תכונות של ECS, ללא כאב הראש של ניהול ECS. מטרת הפוסט הנוכחי היא לעשות סקירה זריזה על הפיצ׳ר החדש, על יתרונותיו ועל חסרונותיו. חשוב לציין, זו סקירה ראשונית, וכדי להבין לעומק את היתרונות והחסרונות, אני אזדקק לכמה חודשים בפרודקשן.
למדה מאחורי הקלעים
נעשה סקירה זריזה על מודל העבודה של למדה.
למדה רצה בתוך קונטיינר, מכיוון שהמודל הוא מודל סרברלס, המשמעות היא שרק, כשמגיעה הבקשה הראשונה, הקונטיינר עולה לאוויר העולם, המשמעות היא שהות של זמן מסוים, עד שהקוד בתוך ה-handler מתחיל לרוץ. ההתנהגות הזאת נקראית cold start, והיא אופיינית לכל שירות סרברלס אמיתי.
.png)
מרגע שהקונטיינר עלה לאוויר העולם, כל הבקשות, אשר ינותבו לקונטיינר הספיציפי הזה ירוצו יותר מהר, וההתנהגות הזאת נקראת warm start.
מודל עבודה נוסף של למדה הוא מודל בקשה פר קונטיינר, כל בקשה חדשה מנותבת לקונטיינר נפרד, מודל העבודה שהוא מאוד נפוץ בשרתי web של מספר בקשות, לא קיים בלמדות, המודל הנפוץ יותר מאפשר שימוש יעיל יותר במשאבי המחשוב.
נעלה דרגה אחת למעלה, הקונטיינר של הלמדה רץ בתוך מכונת EC2, המכונה מנוהלת ע״י AWS, ומאפייני המכונה משפיעים של המשאבים שזמינים ללמדה, לדוגמא, סוג המעבד, תפוקת כרטיס הרשת, מהירות הדיסק וכדומה. מכיוון שהדבר שקוף עבורנו ונקבע לחלוטין ע״י AWS אנו מוגבלים במה שהלמדה יכולה לעשות, צריך gpu? אין אפשרות, צריך יותר זכרון? אתם מוגבלים ב-10GB, צריך כרטיס רשת מהיר? הבנתם את הכיוון…לא אפשרי.
אז מה השתנה? המון
Bring your own EC2 (BYE)
החידוש הוא שמעתה ניתן להריץ למדה בתוך EC2 שאתה כמפתח מגדיר, אך החידוש לא טמון אך ורק ב-instance type שאתה מגדיר, אלא גם במודל העבודה.
חשוב לציין לפני שאנו צוללים לפתרון, שזו בחירה של הפיתוח האם להשתמש בו, ניתן להמשיך במודל הותיק.
מודל העבודה החדש
הקונטיינר של הלמדה מאותחל במכונת EC2, ברגע שהמכונה עלתה, תמיד יש מכונה ותמיד יש קונטיינר (יותר מאחד) שזמין לעבודה, קונטיינר שכזה שזמין לעבודה, נקרא סביבת ריצה (Execution environment). כל סביבת ריצה של למדה מסוגלת לטפל ביותר מבקשה אחת במקביל וסביבת הריצה לעולם לא תסיים את עבודתה, הוא תמיד ממתינה לבקשה הבאה, כן אין cold start יותר במודל העבודה הזה, לא רק זאת, אתם נהנים מהמשאבים שמוקצים למכונת ה-EC2 שבחרתם, כרטיס רשת יותר מהיר, gpu (כן כן, אני מסתכל עליהם מפתחי ML) וכדומה.

כמות הקונטיינרים בכל מכונת EC2 מוגבל בכמות הזיכרון ובכמות ה-vCPU שמוקצה לכל סביבת ריצה שכזאת. אם לחלקכם המודל נראה מוכר, כי זה מודל שמאוד מזכיר container orchestrators אחרים כגון ECS, EKS וכדומה ובכלל זה מודל פיתוח מאוד סטנדרטי בימינו ולא מזכיר כל כך את הלמדה כפי שאנו מכירים אותה, אז מה היתרונות במודל הזה? למה להשתמש בו ולא ב-ECS?
נהנים מהאינטגרציה האוטומטית של למדות עם שירותים אחרים של AWS, אינטגרציה ששווה זמן וכסף.
בניגוד ל-ECS ודומיו, אין צורך להגדיר ALB, או קונפיגורציות רשת מורכבות ובכלל, אם אי פעם הרמתם ECS, אתם יודעים כמה קוד שבלוני אתם צריכים לייצר (אם כי הדברים השתנו משמעותית עם ECS Express). הכל מנוהל ע״י AWS.
אז על פניו, זו נשמעת כהחלטה מתבקשת, מה הצורך להמשיך ולהשתמש במודל הסטנדרטי של למדה? ישנן חסרונות והן עשויות להיות מאוד משמעותיות עבורכם.
מספר בקשות במקביל? המשמעות היא שבמידה והקוד שלכם מכיל קטע קריטי, עליכם לוודא שלא נוגעים בו במקביל, עד כה זו בעיה שלא הפריעה לכם, כעת, צריך לקחת אותה בחשבון.
ניצול זיכרון, מעלים קובץ? מורידים קובץ, לפתע כמות הזיכרון יכולה לגדול משמעותית, צריך לחשוב על כך.
בעיות של resource exhaustion, כגון זליגות זכרון, ישפיעו עליכם.
עלויות - תמיד יש מכונות EC2 שרצות, אין יותר Scale to Zero, תמיד משלמים (אבל מצד שני ניתן לקבל הנחות גדולות יותר על ה-EC2). כבר לא הייתי קורא לפתרון סרברלס.
סקיילינג - בניגוד ללמדות שמסוגלות לעשות סקייל מאוד מהיר (אלפים בשניה), כאן ישנה מגבלה, אם מכונות ה-EC2 התמלאו להן, צריך להרים אחת חדשה, זה לא תהליך של מילי שניות אלא יכול גם להגיע למספר דקות, תלוי במכונות שבחרת.
אני עדין שואל את עצמי למה כדאי להתחיל לעבוד במודל שכזה? ואין לי עדין תשובה טובה, כמובן במידה ואתם צריכים את היכולות הספיציפיות של GPU ואתם מעוניינים לעבוד על למדות, אז לחלוטין המודל הזה מתאים. לא הייתי מתחיל איתו, אבל זו רק התרשמות ראשונית, אולי אשנה את דעתי בהמשך.
רגע לפני שקופצים להדגמה חיה, אני רוצה להתעכב על מנגנון הסקיילניג
סקיילניג
ישנם שני גורמים שמפיעים על מנגנון הסקיילינג:
כל למדה בודדת יכולה לטפל במספר בקשות בנפרד, כיצד הדבר ממומש מאוד תלוי בשפת הפיתוח, לדוגמא NodeJS, משתמש ברעיון של worker, כשכל worker מסוגל לקחת מספר בקשות (במודל async) במקביל. כל worker מצופה לטפל בעד 64 בקשות במקביל. שימו לב לכל worker יש זיכרון משותף.
ב-Python, שלא כל כך תומך ב-async יש פרוסס נפרד עבור כל בקשה. ממליץ לקרוא את הדוקמנטציה בנושא.כמות סביבות הריצה. כשכל סביבת ריצה מכיל יחידת עבודה, לדוגמא worker ב-nodejs ו-process ב-python. מספר סביבות הריצה תלוי במספר ה-vCPU שיש במכונת ה-EC2.
לאחר שדיברנו על מודל העבודה, בוא נראה איך הוא נראה.
איך מקנפגים
צורת העבודה החדשה הזאת דורשת מאיתנו להגדיר משאב חדש בשם Capacity Provider.
Capcity Provider
כפי שרשמתי הלמדות רצות בתוך EC2, מטרת ה-Capacity Provider, היא להגדיר איך המכונות הללו מנוהלות, כלומר כמה מכונות לייצר לכל היותר? מה סוג המכונות? ומתי להרים מכונה חדשה? מייצרים Capacity Provider דרך הקונסול של הלמדה.
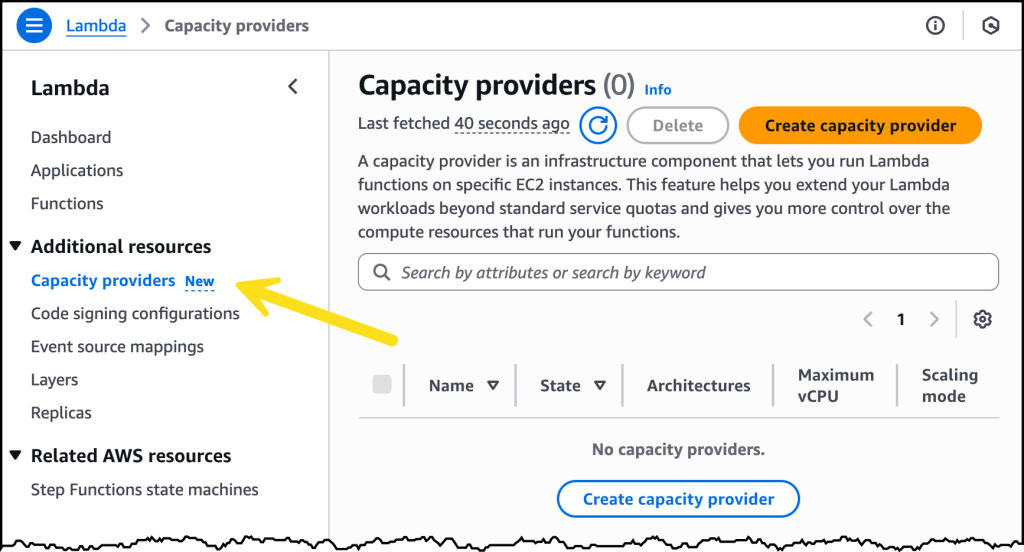
החלק הכי חשוב בהגדרות הוא המגבלות על מכונות ה-EC2, מאוד תלוי דרישות (GPU ודומיו), אם כי ההמלצה, במידה ואין לכם דרישות מיוחדות היא לתת ל-AWS לבחור.
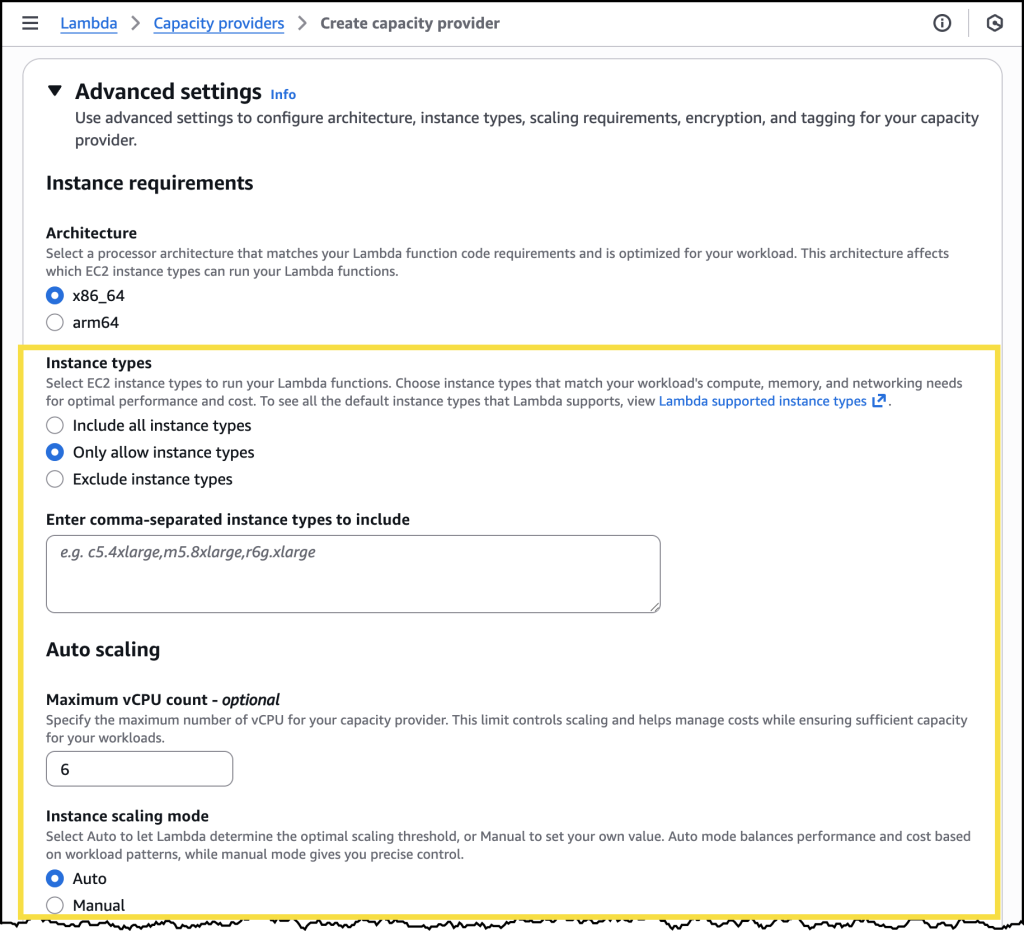
לאחר יצירת ה-Capacity Provider, ניתן לייצר למדה חדשה ולבחור את ה-capacity provider החדש
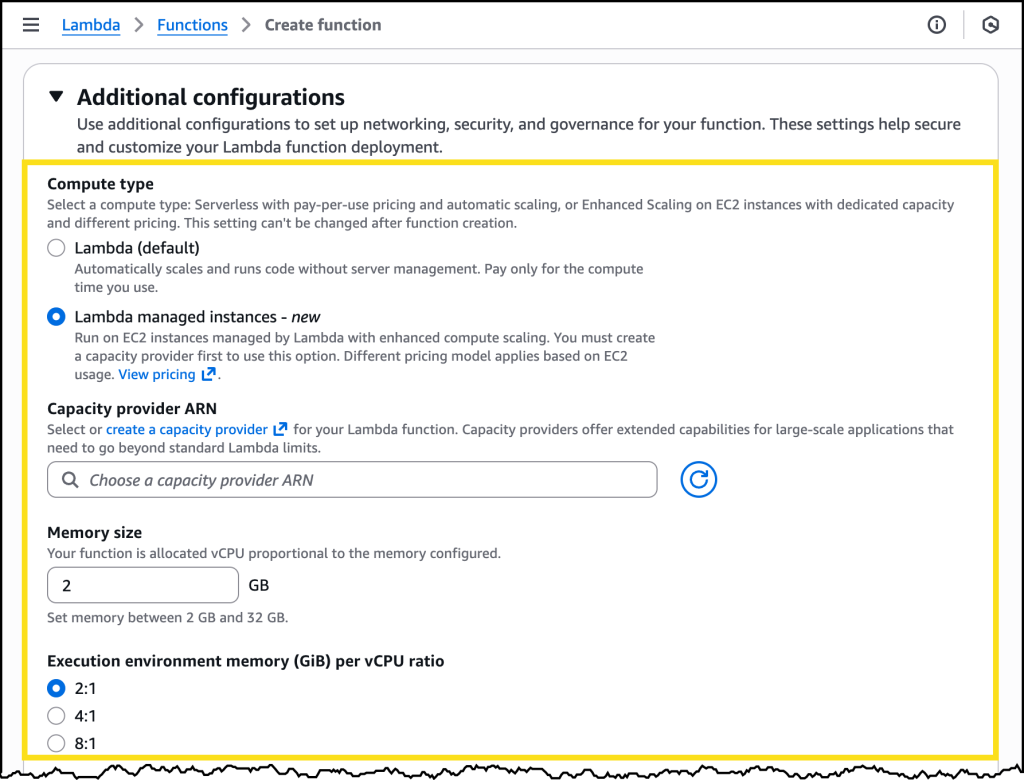
כאן הקופיגורציה תשפיע על מה מוקצה לכל worker או process, לדוגמא כמות זיכרון ויחס זיכרון ל-vCPU, היחס יגדיר כמה vCPU יוקצה ל-worker שלכם, בדוגמא הנ״ל, לכל 2GB זיכרון יוקצה vCPU אחד. ההגדרות הללו מאוד תלויות במה שהלמדה שלכם עושה, במידה והיא cpu intensive אתם תרצו פחות זיכרון ויותר vCPU ולכן תבחרו יחס נמוך יותר, לעומת מטלות שבהם תרצו יותר זיכרון ופחות vCPU. שימו לב לנקודה חשובה, אין יותר חלקי vCPU כפי שנהוג בלמדה רגילה, אלא מכפלות שלמות, ההגיון שעומד מאחורי זה שכל worker צריך לטפל בכמה בקשות ולא בבקשה בודדת.
Observability/Performance
כמה מילים על Observability, המטריקות הישנות עדין תקפות, שהן כמות קריאות, משך קריאה וכדומה, אך הן לא מודדות ריצה של למדה בודדת אלא ריצה של בקשה בודדת,
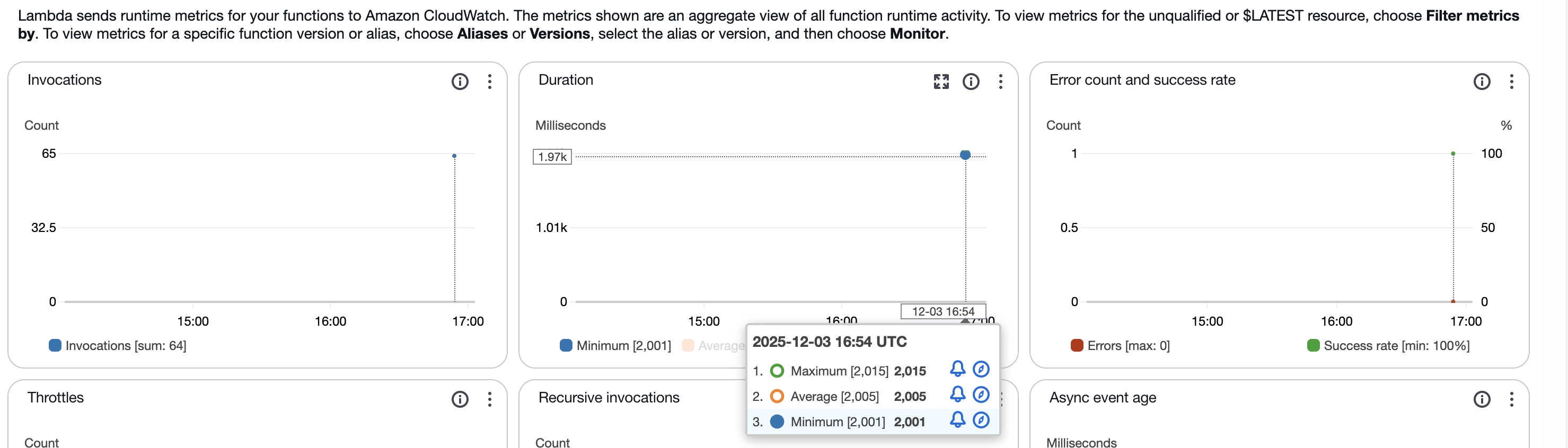
אך התווספוו להן מטריקות נוספות, חשובות, זכרו, אנחנו עוברים למוד דמוי ECS ולכן ניצולת הזיכרון וה-CPU בכל סביבת ריצה היא חשובה. המספרים כאן יוכלו להגיד לכם אם יחס הזיכרון vCPU שבחרתם הוא נכון או לא נכון.
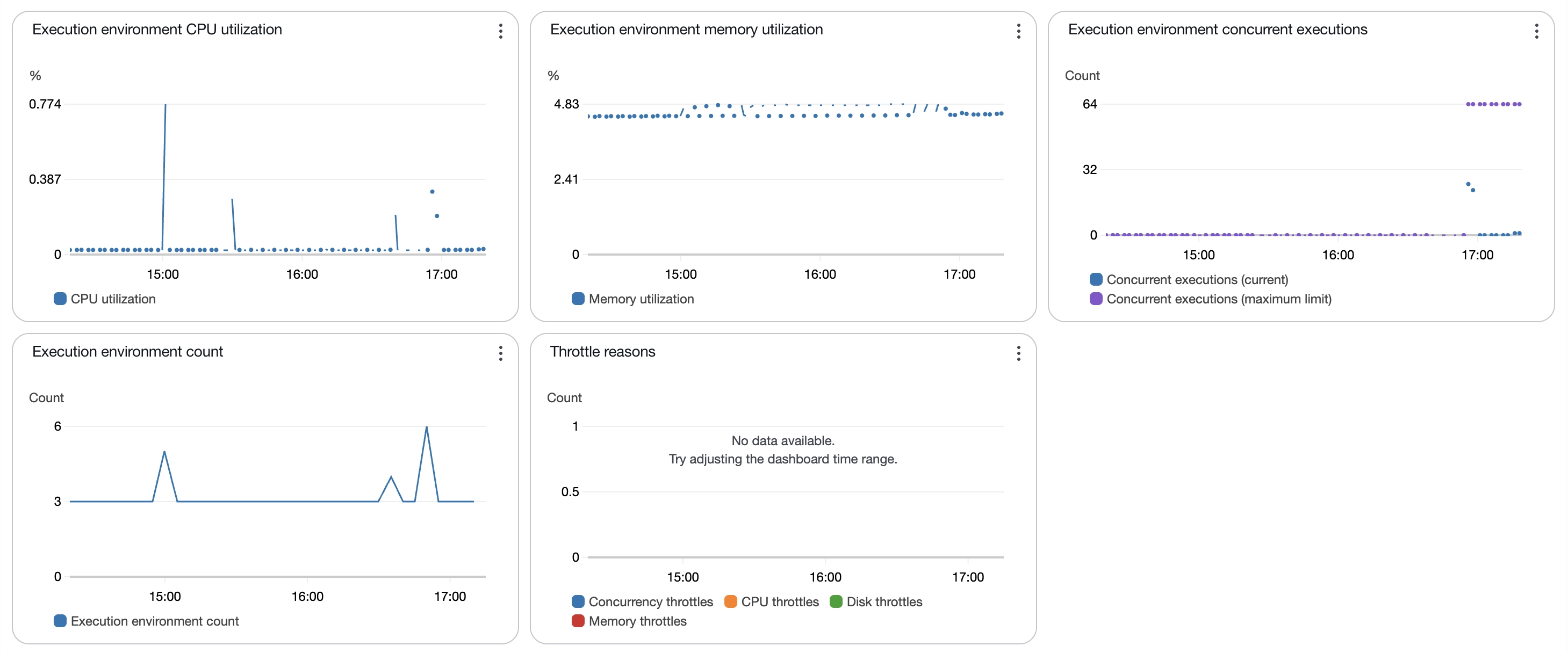
ומעל העל, אתם גם מנהלים שרתי EC2 תחת ה-Capacity Provider, המורכבות עולה כאן.
לסיכום, ישנם המון נושאים שלא נגעתי בהם, שאני עדין לא מבין את המשמעות שלהם:
אבטחה - AWS אומרים במפורש שההפרדה מתבצעת רק ברמת ה-capacity provider, כלומר לא ניתן לסמוך על הפרדה מלאה, שזה שונה לחלוטין מהמודל הקודם שהתבסס על firecracker.
Observability - כל המידע של אותו worker נרשם לאותו log stream, כלומר יהיו לוגים משולבים של מספר ריצות יחד באותו לוג, עם
requestIdשונה. כמו כן יש מטריקות חדשות שצריך לעקוב אחריהן. כמו הניהול והאופטמזיציה הופכת להיות מורכבת יותר, ההסכלות היא לא רק ברמת הריצה הבודדת, אלא גם ברמת סביבת ריצהעלויות - נושא העלויות הוא קצת מורכב יותר, ולמעשה אין יותר עלות על משך זמן ריצה של הלמדה (שעבורי זה אומר שזה כבר לא סרברלס) אלא רק על השימוש ב-EC2 + אקסטרה תשלום ל-AWS על העבודה מאחורי הקלעים של ה-routing. מצאתי מחשבון נחמד, שניתן להשוות עלויות.
מוזמנים לשתף את דעתכם בתגובות.
תגובות